

Possible research projects in the Bonvin Lab
Dissecting and predicting biomolecular complexes
A structural bioinformatics and modelling project from the Computational Structural Biology Research group.
Contact person: Prof. Dr. A.M.J.J. Bonvin (a.m.j.j.bonvin@uu.nl) Bloembergen NMR building, room 1.22, phone: 030-2533859
Introduction
The fact that an entire genome can nowadays be sequenced for less than $1,000 led to a boom in genetic information, which in turn attracted particular attention to biomolecular interactions. It is estimated that a human cell is regulated by over 300,000 protein interactions, but only a small fraction of these have been structurally characterized by experimental methods such as X-ray crystallography or Nuclear Magnetic Resonance (NMR) spectroscopy. Other biochemical and biophysical methods can, however, obtain partial structural information on these interactions, while bioinformatics analysis of the can also contribute important evolutionary data. Combining these predictions and/or partial experimental information with methods for structure prediction of interactions – docking – allows the generation of atomic structural models that complement the experimental techniques.
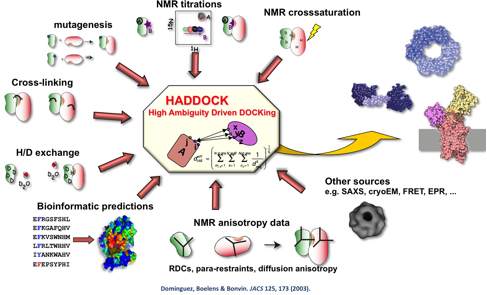
All docking methods share three common elements: first, three-dimensional (3D) structural models of the individual components must be available; second, they must explore the conformational landscape of the interaction and generate candidate structural models of the complex, what is called sampling; finally, they must assess the generated models and select those that are more likely to be representatives of the native complex, what is called scoring. We have developed for this purpose an information-driven docking approach called HADDOCK (https://www.bonvinlab.org ). HADDOCK is also available as a webserver, together with several other services operated by our group. The server is used by more than 18,500 users worldwide. It currently is one of the best docking methods in the world as assessed in a blind international competition. HADDOCK is unique because it can use external information to bias the sampling towards the ‘right’ answer. Nevertheless, there are still many challenges related to describing larger and more complex systems, improving our protocols to handle different types of molecules, improving our scoring functions and assessing the impact of a variety of data and energy functions on the prediction performance.
Do you want to get a feeling of our HADDOCK portal? Check the live demo given at the EOSC-Hub week 2020 conference, where we show in particular how to setup a refinement run in HADDOCK2.4 to assess the impact of a mutation, using the interaction between SARS-CoV2 RBD domain and a peptide extracted from the ACE2 receptor as an example.
View demo
Possible projects
We are looking for motivated students to help us further develop HADDOCK. Examples of possible projects are:
- Develop protocols and assess how well HADDOCK can predict protein-oligosaccharide complexes.
- Develop protocols and assess how well HADDOCK can predict protein-RNA complexes.
- Develop protocols and assess how well HADDOCK can predict RNA-RNA complexes.
- Explore antibody design with HADDOCK3.
- AI-based scoring of protein-protein models (combine HADDOCK and AlphaFold or related)
You will work independently - although with guidance - on your own project, which will involve basic computer skills (can be learned on the job), and biochemistry/biophysics knowledge of biomolecular structures. And you will make a real-world impact in structural biology research considering the large and worldwide user base of HADDOCK!
Skills acquired
- Molecular modelling / integrative modelling
- Molecular graphics
- Bioinformatics
- Linux and scripting
- Programming (e.g. Python)
- Data analysis, machine learning
- High performance/throughput computing
- General biomolecular structural biology knowledge
References
• J.P.G.L.M Rodrigues and A.M.J.J. Bonvin. Integrative computational modeling of protein interactions. FEBS J., 281, 1988-2003 (2014).