

Protein-DNA docking Using HADDOCK High-Ambiguity Driven DOCKing
This tutorial consists of the following sections:
- Introduction
- About this tutorial
- Introduction to the tutorial test case
- Understanding the ambiguous interaction restraints
- Visualizing the ambiguous interaction restraints
- Extracting a single structure from the NMR ensemble using PBD-tools (optional)
- Preparing the HADDOCK2.4 web server run
- Protein-DNA docking using the HADDOCK web server
- Preparing the Cro-OR1 docking run
- Analysis of the docking run
- Congratulations!
- References
Introduction
Structures of protein-DNA complexes fulfill a key role in our understanding of the complex regulatory mechanisms in the living cell. With the ever-increasing number of putative DNA-interacting proteins, there is a need for high-throughput structural biology pipelines.
However, not all biomolecular complexes are that straightforward to solve using experimental methods such as X-ray crystallography and Nucleic Magnetic Resonance (NMR) spectroscopy. Indeed, complexes that engage in transient interactions are, by definition, highly dynamic during interaction, while too big ones remain still a challenge for structural experimental techniques.
Computational methods for the calculation of structural models at atomic resolution have proven to be a valid toolset to help overcome some of these experimental limitations. Especially docking algorithms are becoming increasingly popular. These algorithms aim to solve the structure of a complex from its native constituents using various computational approaches. While very performant for protein-protein interactions, many of these algorithms suffer limitations when trying to model protein-DNA complexes such as the location of the interaction interfaces and dealing with conformational change upon complex formation.
This tutorial will introduce HADDOCK (High Ambiguity Driven DOCKing) [1] as a method to overcome some of the limitations associated with protein-DNA docking.
About this tutorial
In this tutorial, we aim to introduce you to basic concepts of protein-DNA docking using HADDOCK2.4 webserver. For a complete protein-DNA docking using HADDOCK 2.4, including the generation of Ambiguous Interaction Restraints (AIRs) and starting structures, visit the advanced tutorial on protein-DNA docking.
What is new in this tutorial?
You will perform a docking of a protein-DNA system composed of 3 biomolecules (2 proteins and 1 DNA). All of these molecules are in their unbound conformation.
- Introduction on the use of symmetry restraints.
Using this tutorial
You should be able to go through this tutorial in about 1 hour. We will be using the PBD-tools webserver for preprocessing a PDB file (optional) and the HADDOCK 2.4 webserver https://wenmr.science.uu.nl/haddock2.4/ to perform the docking.
- R.V. Honorato, M.E. Trellet, B. Jiménez-García, J.J. Schaarschmidt, M. Giulini, V. Reys, P.I. Koukos, J.P.G.L.M. Rodrigues, E. Karaca, G.C.P. van Zundert, J. Roel-Touris, C.W. van Noort, Z. Jandová, A.S.J. Melquiond and A.M.J.J. Bonvin The HADDOCK2.4 web server: A leap forward in integrative modelling of biomolecular complexes. Nature Protoc, 19, 3219–3241 DOI: 10.1038/s41596-024-01011-0 (2024)
Throughout the tutorial, coloured text will be used to refer to questions or instructions, and/or PyMOL commands.
This is a question prompt: try answering it! This an instruction prompt: follow it! This is a PyMOL prompt: write this in the PyMOL command line prompt!
Tutorial data set
In this tutorial you will perform a protein-DNA docking using the bacteriophage 434 Cro repressor protein and the OR1 operator as an example case. All the tutorial data are made available as a zip archive and can be downloaded at the following link.
Extract the archive
You need to decompress the tutorial data archive. Move the archive to your working directory of choice and extract it. You can either extract the archive by just selecting “extract” option.
Extraction of the archive will present you with a new directory called protein-DNA_basic that contains a number of files and directories:
- an NMR ensemble of the 343 Cro repressor structure (
1ZUG_ensemble.pdb) - a single structure coming from the NMR ensemble (
1ZUG.pdb) with the disordered residues removed - the structure of the OR1 operator in B-DNA conformation (
OR1_unbound.pdb) - the ambiguous restrains (
ambig_pm.tbl), created with a combination of experimental from literature information. A detailed explanation of how to generate these restraints can be found here. - the X-ray structure of the complex
3CRO_complex.pdbused as reference to compare with the docking results - the
prot-dna-outputs-examples/directory holds a sample of the results obtained by doing this tutorial.
To obtain more detailed information about how to obtain these files, please refer to the advanced tutorial on protein-DNA docking.
Where can I find more information?
An elaborate discussion of all the concepts of protein-DNA docking and the various options of the HADDOCK docking software is beyond the scope of this tutorial. Where needed, some concepts will be explained throughout the tutorial to maintain the readability and flow of this document. The tutorial ends with a reference block that provides links to in depth literature or Internet documentation about various topics.
What if I do not find an answer to my questions?
It is always possible that you have questions or run into problems for which you cannot find the answer in the regular documentation. Here are some additional links that you can find answers to your questions:
- Bioexcel user forum: https://ask.bioexcel.eu/c/haddock/6
- HADDOCK Help Center: https://wenmr.science.uu.nl/haddock2.4/help
- HADDOCK software and online manual: https://www.bonvinlab.org/software/haddock2.4/manual/
Tutorial icon conventions
Throughout the tutorial we will use the following special fonts and icons to perform certain tasks or draw your attention:
This is a question prompt: try answering it! This an instruction prompt: follow it! This is a PyMOL prompt: write this in the PyMOL command line prompt!
Introduction to the tutorial test case
To illustrate our protein-DNA docking protocol we will use as an example the complex between the bacteriophage 434 Cro repressor proteins and the OR1 operator.
Cro is part of the bacteriophage 434 genetic switch
Cro is a repressor protein of the temperate bacteriophage 434. It works in opposition to the phage’s repressor protein to control the genetic switch. The competition between both determines whether the phage embarks on a lytic or lysogenic lifecycle after infection. The repressors compete to gain control over an operator region containing three operators that determine the state of the lytic/lysogenic genetic switch. If Cro wins the late genes of the phage will be expressed and the result is lysis. If the phage repressor wins the transcription of Cro, genes is further blocked and repressor synthesis is maintained, resulting in a state of lysogeny.
Structure of the Cro-OR1 complex
The structure of bacteriophage 434 Cro in complex with the OR1 operator was solved by X-ray crystallography ([4], Figure 1). We will use this structure as reference (or target) during the remaining of the tutorial. Cro functions as a symmetrical dimer. Each subunit contains a helix-turn-helix (HTH) DNA binding motif. This is a typical DNA major groove-binding motif. Helices α2 and α3 are separated by a short turn. Helix α3 is the recognition helix that fits into the major groove of the operator DNA and is oriented with its axes parallel to the major groove. The side chains of each helix are thus positioned to interact with the edges of base pairs on the floor of the groove. Non-specific interactions also help anchor Cro to operator DNA. These include H-bonds between main chain NH groups and phosphate oxygen’s of the DNA in the region of the operator. Cro distorts the normal B-form DNA conformation: the OR1 DNA is bent (curved) by Cro, and the middle region of the operator is overwound, as reflected in the reduced distance between phosphate backbones in the minor groove.
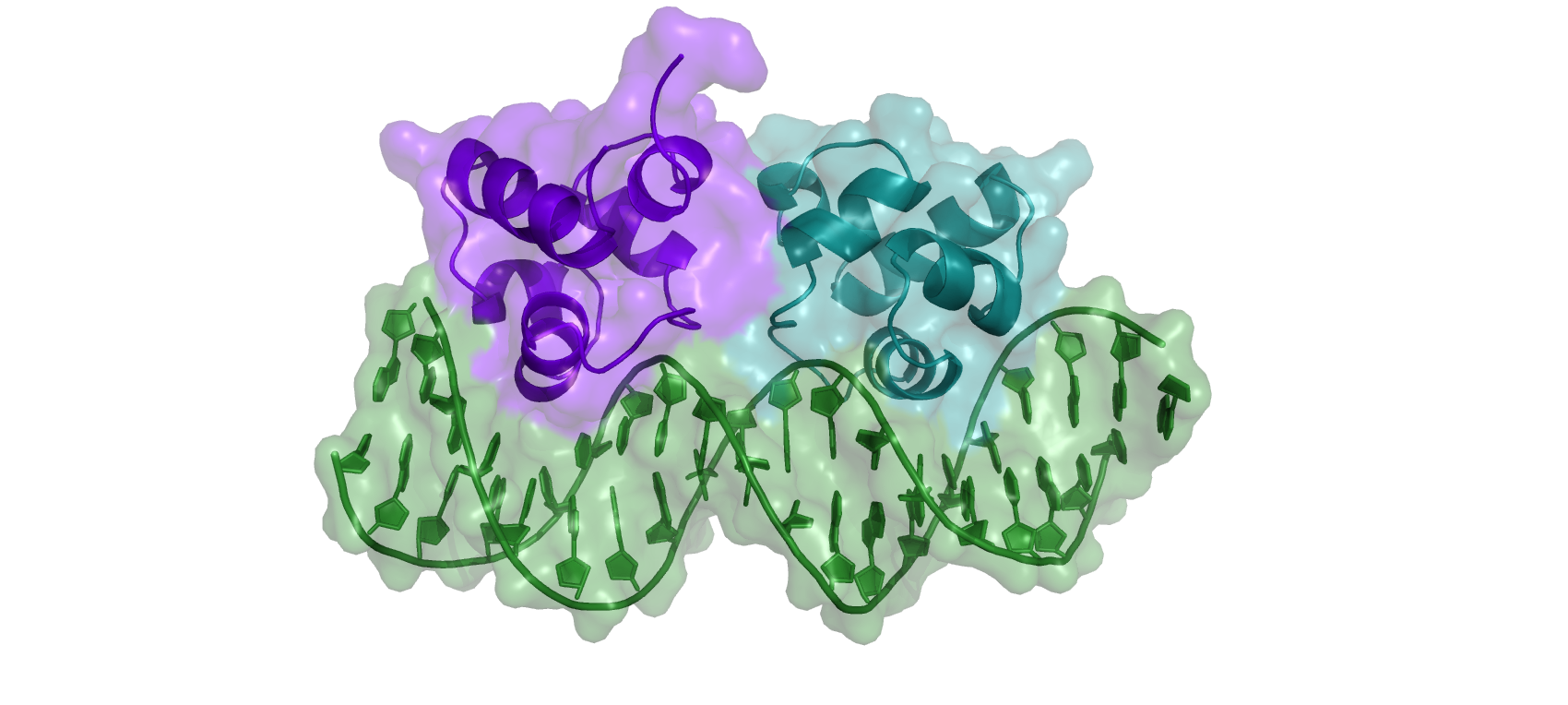
Figure 1: Cartoon representation of the X-ray structure (PDB id 3CRO) of the bacteriophage 434 Cro-OR1 complex.
Understanding the ambiguous interaction restraints
The ambiguous interaction restraints are defined in the ambig_pm.tbl file and the creation of such file is explained in detail here.
Let’s have a look at the first lines of the file:
! Protein first monomer restraints
!
assign ( resid 31 and segid A)
(
( resid 24 and segid C and (name H41 or name H42 or name N3 or name C4 or name C5 or name C6))
or
( resid 17 and segid C and (name H1 or name H21 or name N7 or name O6 or name C5 or name C6 or name C8))
or
( resid 25 and segid C and (name H61 or name H62 or name N1 or name N7 or name C5 or name C6 or name C8))
...
) 2.000 2.000 0.000
After the two commented lines (starting with !), the first line of the file indicates that residue 31 of chain A is should be involved in the interaction with the DNA (chain C), and that the possibly interacting residues are defined by the following lines (DNA bases 24, 17 and so on, each one with a few atoms). If one of these residues satisfies the distance requirement, the interaction restraint is considered satisfied.
The same syntax is followed for the DNA molecule:
!
! DNA restraints
!
assign ( resid 16 and segid C and (name H3 or name O4 or name C4 or name C5 or name C6 or name C7))
(
( resid 29 and segid A)
or
( resid 31 and segid A)
or
( resid 32 and segid A)
or
( resid 30 and segid A)
or
( resid 28 and segid A)
or
( resid 34 and segid A)
) 2.000 2.000 0.000
which is coupled to a set of amino acids on the protein side (residues 29, 31, 32, 30, 28 and 34 in this case).
Visualizing the ambiguous interaction restraints
Let’s start by visualizing how the interacting residues used to drive the docking are distributed on the protein.
File menu -> Open -> select 1ZUG_ensemble.pdb
We will now highlight the amino acids that are supposed to be at the interface. In PyMOL type the following commands:
color white, all
select interacting, (resi 28+29+30+31+32+34+35)
color red, interacting
Why is residue 33 excluded from these amino acids?
Let us now switch to a surface representation to inspect the binding site.
color white, all
show surface
color red, interacting
Inspect the surface.
See surface view of the interacting residues expand_more

Extracting a single structure from the NMR ensemble using PBD-tools (optional)
We understood how the NMR ensemble of protein has a disordered tail at the end of the protein chain. Since this disordered region is not involved in the binding, we can simply take the first structure from the ensemble and remove this region. This can be done using the PBD-tools program (see Figure 2). Docking with an ensemble of conformations is still possible.
First open your web browser to go to https://wenmr.science.uu.nl/pdbtools/ and choose Submit a pipeline.
Here, we fetch the NMR ensemble directly from the PDB database by typing 1ZUG in the PDB Code field.
Fetch the NMR ensemble of 1ZUG from the PDB using the PDB code.
Now we will split our ensemble in several models.
Choose ‘pdb_splitmodel’ from the Pre-processing panel and click on +Add a new block.
Then we need to clean our pdb structure by removing all water, ion or other non-protein atoms as a result from the crystallisation process.
Choose ‘pdb_delhetatm’ and click on +Add a new block.
Now we will remove the disordered region at the end of the protein chain.
Choose ‘pdb_selres’ and click on +Add a new block
Once the ‘pdb_selres’ block is added to the pipeline, add 1:66 to the selection box.
This will select all the residues from 1 to 66, thus removing the disordered region at the end of the protein chain.
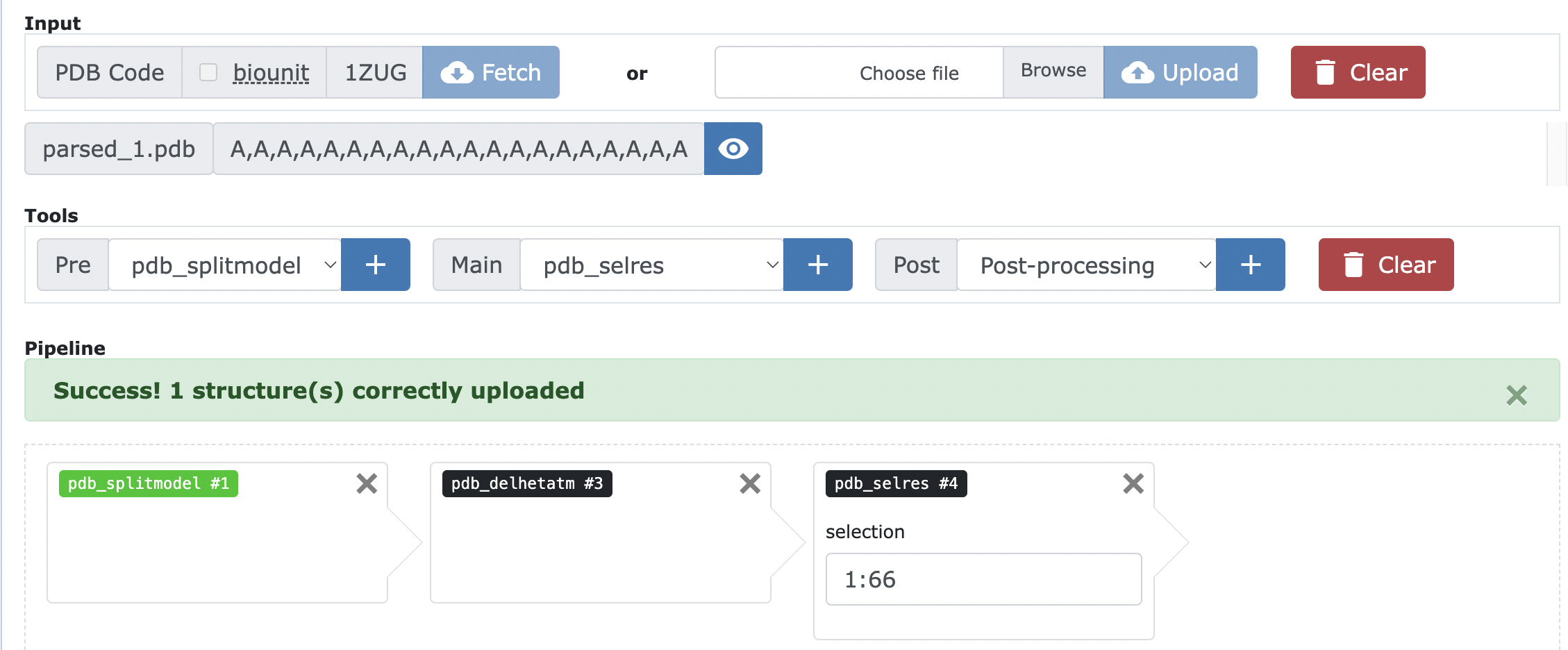
Figure 2:visualization of the PBD-tools pipeline.
Once you have all commands in our pipeline click on Run.
On the result page we can see twenty output files, each corresponding to one model of the ensemble. For each the command used to run PBD-tools is also given.
If you wish to save the pipeline after this step, click on Download JSON pipeline.
Note:: in case you want to use the (trimmed) ensemble during docking you can simply add the ‘pdb_mkensemble’ command at the end of the PBD-tools pipeline. This will merge the 20 trimmed conformations in a single PDB file.
Preparing the HADDOCK2.4 web server run
The introduction of the HADDOCK web server in 2008 and the eNMR Grid-enabled web server shortly after, changed a lot in the docking community. HADDOCK 2.4 is now available for commercial use through https://wenmr.science.uu.nl/haddock2.4/ after registration. As the years progressed, new machine learning based modelling tools started to emerge, such as AlphaFold. Although machine learning based methods eased modelling of a variety of protein-protein complexes, it cannot be used for protein-DNA or protein-RNA modelling. Therefore, HADDOCK remain a convenient tool to be used for protein-DNA docking. The combination of automated setup procedures, vigorous checks of the input, best practice defaults, easy access to many of the powerful HADDOCK features and access to ample computer resources has made docking available to a wide audience.
Protein-DNA complexes are one of the more challenging systems to dock but also here the HADDOCK web server assists the user with a number of automated routines to setup the system correctly. This tutorial will introduce you to these features.
Using this part
With the protein and DNA starting structures available and the Ambiguous Interaction Restraints setup, you can start setting up your docking using the HADDOCK web server.
This part will introduce you to the use of the HADDOCK web server for the docking of protein-DNA systems.
Although basic two-body protein-DNA docking can be performed using the HADDOCK Easy interface privileges, the use of custom Ambiguous Interaction Restraints requires the Expert privileges and the use of additional restraint types such as symmetry restraints, tweaking of the sampling parameters and multi-body docking requires the Guru privileges.
Hence, for this tutorial you will require Guru access privileges.
After registering to HADDOCK from here, you can request access elevation from here.
Protein-DNA docking using the HADDOCK web server
Apart from the default setup procedures and server input checks, the use of DNA requires two additional steps. These are automatically performed by the server when defining one molecule as nucleic acid:
- The server will select the proper nucleic acid topology, parameter and linkage files for the nucleic acid molecule. DNA and RNA are distinguished by their residue namings (single letter for RNA, two letters (starting with a D for DNA), e.g. A or DA for adenine.
- An additional set of restraints will be generated to help maintain the helical structure of the DNA. These include sugar-pucker restraints, nucleotide base planarity restraints, sugar-phosphate backbone dihedral restraints and Watson-Crick hydrogen bond restraints between nucleotides that have been detected to be within pairing distance of one another.
- A constant dielectric constant (epsilon) is selected with a value of 78 by default for both it0 and it1.
Preparing the Cro-OR1 docking run
Setup the Cro-OR1 multi-body docking run using HADDOCK 2.4 webserver.
Input files can be found in protein-DNA_basic directory.
Input data
Name –> Give your run a name. Molecules –> 3
Molecule 1 - input:
Molecule 2 - input:
Molecule 3 - input:
Click Next at the bottom of the page to proceed to “Input parameters” section.
This will upload the structures to the HADDOCK webserver where they will be processed and validated (checked for formatting errors).
The server makes use of Molprobity to check side-chain conformations, eventually swap them (e.g. for asparagines) and define the protonation state of histidine residues.
Input parameters
Leave all parameters to their default values and press Next at the bottom of the page.
Docking parameters
Distance restraints:
Energy and interaction parameters:
Symmetry restraints:
Here we want to enforce a pairwise (C2) symmetry between the two protein monomers.
For more information on symmetry restraints, please refer to the corresponding page in the HADDOCK2.4 manual.
Click Submit at the bottom of the page to launch the docking.
Analysis of the docking run
In case you are running short in time, a permanent link to the docking results of this tutorial is made available at the following link.
Analysis on the HADDOCK result page
After you run has finished (approximately 1 hour, depending on the load of the server), you will be presented with a result page in which the top10 (max) clusters and their statistics are displayed (Figure 2).

Figure 3: HADDOCK2.4 results page of protein-DNA docking of the first cluster, composed of 124 models.
Note: The bottom of the page shows a graphical representation of the results, showing the distribution of the solutions for various measures (HADDOCK score, van der Waals energy, …) as a function of the Fraction of Common Contact and RMSD from the best generated model (the best scoring model), as presented in Figure 4. The graphs are interactive: E.g. you can zoom in on specific areas of the plot.
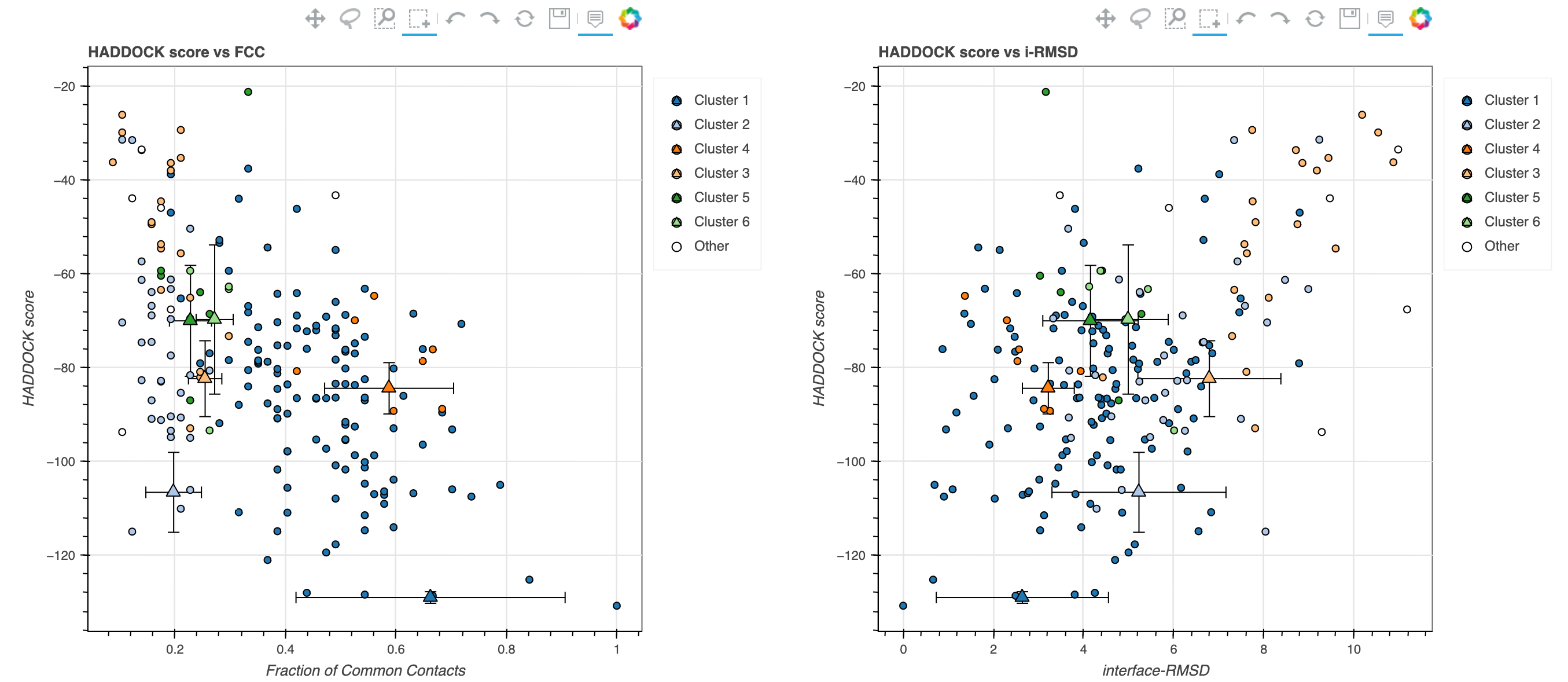
Figure 4: HADDOCK2.4 graphical representation of the results.
Finally, the bottom graphs show the distribution of scores (van der Waals, Electrostatics and AIRs energy terms) for the various clusters.
Analysis on your own computer
After having analysed the statistics on the HADDOCK2.4 result page, you can download an archive containing all cluster representatives by clicking on the _ download all cluster files_ link just above the statistics of the first-ranked cluster.
Unpack this archive and then open a new PyMol session and type the following commands in the prompt to superimpose the docking complex Y from cluster X to the reference structure.
load clusterX_Y.pdb
load 3CRO_complex.pdb
align clusterX_Y, 3CRO_complex
Look at the various cluster. Can you find the differences between the various clusters?
Is the top-ranked cluster by HADDOCK also the closest to the reference crystal structure?
Congratulations!
You have made it to the end of this basic protein-DNA docking tutorial. We hope it has been illustrative and may help you get started with your own docking projects.
Happy docking!
References
1) Dominguez, C. et al. (2003). HADDOCK: a protein-protein docking approach based on biochemical or biophysical information. JACS 125, 1731-1737
2) van Dijk, M. et al. (2006). Information-driven protein-DNA docking using HADDOCK: it is a matter of flexibility. N.A.R. 25, 3317-3325
3) van Dijk and Bonvin (2010) Pushing the limits of what is achievable in protein-DNA docking: benchmarking HADDOCK’s performance. N.A.R. 38, 5634-5647
4) Mondragón and Harrison (1991). The phage 434 Cro/OR1 complex at 2.5 A resolution. J Mol Biol 219, 321-334
More information about the HADDOCK web server:
- de Vries et al. (2010). The HADDOCK web server for data-driven biomolecular docking. Nat Protoc 5, 883-897