

Molecular Dynamics Simulation of the p53 N-terminal peptide
General Overview
This tutorial introduces Molecular Dynamics (MD) simulations of proteins. The simulation protocol can be used as a starting point for the investigation of protein dynamics, provided your system does not contain non-standard groups. By the end of this tutorial, you should know the steps involved in setting up, running, and analyzing a simulation, including critically assessing the choices made at the different steps.
- Use of virtual machines (VMs)
- A bite of theory
- Introduction and Outline
- Preparing the System
- Selecting an initial structure
- Preparing the initial structure
- Structure Conversion and Topology Generation
- Periodic Boundary Conditions
- Energy minimization of the structure in vacuum
- Solvating the simulation box
- Addition of ions: counter charge and physiological concentration
- Energy minimization of the solvated system
- Restrained MD – relaxation of solvent and hydrogen atoms
- Coupling the barostat – simulating in NPT conditions
- Releasing the position restraints
- Production Simulation
- Analysis of the Molecular Dynamics Simulation
- Visually inspecting the simulation
- Quantitative Quality Assurance
- Convergence of the thermodynamical parameters
- Calculation of the minimum distance between periodic images
- Conformational dynamics and stability I – Radius of Gyration
- Conformational dynamics and stability II – Root Mean Square Fluctuation (RMSF)
- Conformational dynamics and stability III – Root Mean Square Deviation (RMSD)
- Structural Analysis
- Analysis of time-averaged properties
- Picking representatives of the simulation
- Congratulations!
Use of virtual machines (VMs)
For this module of the practical, we will be using NMRbox. NMRbox offers cloud-based virtual machines for executing various biomolecular software that can complement NMR (Nuclear Magnetic Resonance) experiments. NMRbox users can choose from 261 already installed software packages, that focus on various research topics such as metabolomics, molecular dynamics, structure, intrinsically disordered proteins or binding. One can search through all available packages on https://nmrbox.org/software.
Register
To use virtual machines through NMRbox, one needs to register, preferably with their institutional account here. Since the registration has to be manually validated and it can take up to two business days, we strongly encourage students to do so before the course starts. After a successful validation, you will receive an e-mail with your NMRbox username and password that you will be using while accessing your virtual machine.
Accessing NMRbox
To run the virtual machine on a local computer, one needs to install VNCviewer. With the RealVNC client connects your computer to the NMRbox servers with a virtual desktop - graphical interface. More information about the VNC viewer is in the FAQ of NMRbox.
To choose a virtual machine:
- first log into the user dashboard https://nmrbox.org/user-dashboard.
- Download the zip file with bookmarks for the production NMRbox virtual machines.
- Click
File -> Importconnections and select the downloaded zip file. - After importing, you will see the current release virtual machines. You can use any available virtual machine. The user-dashboard provides information on machine capabilities and recent compute load, thus it is clever to choose a less occupied one.
- Double click on one of the VMs. An “Authentication” panel appears.
- Enter your NMRbox username and password.
- Click on the “Remember password” box to have RealVNC save your information.
By default, your desktop remains running when you disconnect from it. If you login to your VM repeatedly you will see a screen symbol next to the VM you connected to recently. For more details follow the quick start guide for using NMRbox with VNCviewer here.
If everything runs correctly you should have a window with your virtual desktop open. In the virtual desktop you have an access to the internet with Chromium as browser or use various programs, including PyMOL. Thus, you could run all three stages of this course here or transfer data between your local machine and the virtual machine. File transfer to and from the VM is quite straightforward and it is described here: https://nmrbox.org/faqs/file-transfer.
In this course we will be working with the command line. For those of you who are not familiar with it, a lot of useful tutorials and documentation can be found here.
To find the terminal, look for a black icon with a $_ symbol on it (named Terminal emulator Use the command line), and click on it.
Once you are familiar with the command line, we can start the Molecular Dynamics tutorial.
Further NMRbox documentation can be found here.
Note: Once you are done using your VM for the day, just log out of it using the top menu button as shown in this 9s video.
Familiarize yourself with Linux, Terminal and Command lines
Here are some useful resources that can help you in starting with Linux:
- Software Carpentry: Introduction to Shell
- Linux tutorial
- Linux Cheat-Sheet
- NMRBox terminal tutorials and documentation
A bite of theory
Molecular Dynamics generate successive configurations of a given molecular system, by integrating the classical laws of motion as described by Newton. Generally, the end product is a trajectory that describes the positions and velocities of the particles in the system throughout the simulation as they vary with time. The following equation describes the motion of a particle of mass \(m\) along the \(x_{i}\) coordinate, where \(F_{x_{i}}\) is the force acting on that particle in that direction. In a realistic molecular system, this equation is expanded to a three-dimensional space.
\[\begin{equation} \frac{d^2 x_{i}}{d t^2} = \frac{F_{x_{i}}}{m_i} \end{equation}\]The force felt by each individual particle is a collection of the effects exerted by other neighboring particles in the system. For protein simulations, the effect of distant particles can be ignored given their negligible contribution, saving substantial computation time in the process.
These forces are calculated using the force field, a set of functions and parameters that approximate the potential energy of the system. These parameters are usually derived either from experiments or high-level quantum mechanical calculations. Although force fields come in many flavors, in the field of biomolecular simulation they generally respect the same principles. First of all, atoms are represented by single particles, with a fixed charge and size. Then, covalent bonds are modelled as springs and follow quadratic energy functions, meaning that they are effectively unbreakable. Finally, the force field is divided in interactions of atoms linked by covalent bonds (bonded interactions) and other interactions (non-bonded) such as electrostatics and van der Waals forces. Most of these interactions are modelled using rather simplistic mathematical functions. For example, in the popular AMBER force field, the non-bonded interactions are described by the following pair of equations:
\[\begin{equation} E_{elec} = \frac{q_{i} q_{j}}{4\pi\epsilon_{0}r_{ij}} \\ E_{vdw} = \epsilon_{ij} \left[ \left(\frac{r_{0ij}}{r_{ij}}\right)^{12} - 2\left(\frac{r_{0ij}}{r_{ij}}\right)^6 \right] \end{equation}\]The molecular dynamics algorithm starts by assigning random velocities to the atoms in the system, from a Maxwell-Boltzmann distribution at the desired temperature. The random seed value, seen in most configuration files of molecular dynamics software, influences this initial attribution. Two trajectories, of the same system with the same random seed are numerically identical, given the deterministic nature of the simulation. To move the atoms from one configuration to another, the algorithm first calculates the forces acting on each atom. From that force, one can determine the acceleration of the atoms and combine these with their positions and velocities at time \(t\) to yield a new set of positions and velocities. The time between the old and new positions is fixed and parametrized at the beginning of the simulation. In biomolecular simulations, the time step (\(\Delta t\)) is usually set to 2 femtoseconds (fs), which is large enough to sample significant dynamics but not as large as to cause problems during the calculations. Too big of a time step can lead to severe issues, such as two atoms overlooking each other, or even end up overlapping! At \(t + \Delta t\), a new set of forces is calculated and so on. The simulation finishes only when there have been enough steps to reach the desired simulation time. Besides all these calculations, biomolecular simulations try to also simulate the conditions inside cells, namely regarding temperature and pressure. There are special algorithms in place, during the simulation, that maintain these two properties constant (or not depending on the setup!).
Despite decades of research, as well as advances in computer science and hardware development, most simulations are able to sample only a few microseconds of real time, although they take several days/weeks running on multiple processors. The millisecond (ms) barrier was broken in 2010, by simulating on a purpose-built computer (Anton). Moreover, the force fields used in biomolecular simulation are approximating the interactions happening in reality. This results in errors in the estimation of energies of interacting atoms and groups of atoms. As such, molecular dynamics are not a miraculous alternative to experiments, nor can the results of simulations be trusted blindly. There must always be some sort of validation, preferably by experimental data. When considering setting up a molecular dynamics simulation, plan it wisely, choosing carefully the setup and the system so that there are a minimum of variables under study. If carried out properly, these simulations remain an unparalleled method in terms of spatial and temporal resolution that are able to shed light on principles underlying biological function and fuel the formulation of new hypotheses.
Introduction and Outline
The aim of this tutorial is to simulate and analyze the conformational dynamics of a small peptide using molecular dynamics algorithms as implemented in the GROMACS software. The following sections outline several preparation steps and analyses. These instructions do not apply to all molecular systems. Take your time to know your system and what particularities its simulation entails.
In NMRBox, after you open the terminal prompt you notice username@machine, where your username is the same as the NMRbox username.
You will find your own copy of the course material in ~/EVENTS/2026-struct-bioinfo-uu/ directory.
You can store your data in your home directory but we recommend creating a new directory where you will store your data and work in.
Note: The data are automatically copied to your home directory under the EVENTS directory provided you have registered for this event on NMRBox. The event can be found at https://nmrbox.nmrhub.org/events. In order to register for the course you need to have an NMRBox account.
Note: In case you are following this tutorial on your own, you will have to manually copy all the required data and edit possibly some files to correct the paths (e.g. the setup.sh and the bashrc scripts). The data for the course can be found once logged in into a VM in the following directory: /public/EVENTS/2026-struct-bioinfo-uu/.This directory will however automatically be copied to your home directory when you register for the course on NMRBox
Open the terminal and create a directory where you will work in with name of your choice: mkdir directory_name
Go to this directory using the cd (for change directory ) command . cd directory_name
Tip: To simplify the workflow one can copy and paste commands to the virtual machine. In case you are not familiar with Unix, note that you can paste copied commands by clicking the middle button of your mouse.
Before we start, we should make sure that we use the proper programs and paths from our directory. This we do by running a setup file which contains basic information about which directories you will be taking your data and programs from.
Preparing the System
The preparation of the system is the heart of the simulation. Neglecting this stage can lead to artifacts or instability during the simulation. Each simulation must be prepared carefully, taking into consideration its purpose and the biological and chemical characteristics of the system under study.
Selecting an initial structure
The first step is obviously the selection of a starting structure. The aim of this tutorial is to simulate a peptide of the N-terminal sequence of the transactivation domain of p53. The sequence of this peptide is given below, in FASTA format:
>sp|P53_MOUSE|18-32 SQETFSGLWKLLPPE
Peptides are often very flexible molecules with short-lived secondary structure elements. Some can even adopt different structures depending on which protein partner they are interacting with, often remaining in a disordered state if free in solution. As such, the effort of using an advanced method such as homology modeling for this peptide is very likely unwarranted. Instead, it is possible, and plausible, to generate structures of the peptide in three ideal conformations – helical, sheet, and polyproline-2 – which have been shown to represent the majority of the peptides deposited in the PDB. Generating these structures is a simple matter of manipulating backbone dihedral angles. PyMOL has a utility script to do so, written by Robert Campbell.
The instructions shown in this tutorial refer only to the helical peptide, for simplicity. The successful completion of the tutorial requires, however, all three conformations to be simulated.
fab SQETFSGLWKLLPPE, peptide_helix, ss=1 or build_seq peptide_helix, SQETFSGLWKLLPPE, ss=helix
Note that both commands will produce the same for helices.
The build_seq script is a home made one, while the fab command is a native PyMOL implementation.
You can get more information on how to use the fab command by typing help fab.
save p53_helix.pdb, peptide_helix
To change residue numbers within PyMOL take a look at the help message of the alter command:
Preparing the initial structure
In case of structures downloaded from the RCSB PDB, it is important to ensure that there are no
missing residues nor atoms, as well as check for the presence of non-standard amino-acids and other small ligands.
Force fields usually contain parameters for natural amino-acids and nucleotides, a few
post-translational modifications, water, and ions. Exotic molecules such as pharmaceutical drugs
and co-factors often have to be parameterized manually, which is a science on its own. Always judge
if the presence of these exotic species is a necessity. In some cases, the ligands can be safely
ignored and removed from the structure. As for missing residues and atoms, except hydrogens, it is
absolutely necessary to rebuild them before starting a simulation.
MODELLER is an excellent program for this purpose.
In addition, some crystals diffract at a good enough resolution to distinguish
water molecules in the density mesh. Save for very particular cases, where these waters are the
subject of the study, the best policy is to remove them altogether from the initial structure. Fortunately,
most of these “problematic” molecules appear as hetero-atoms (HETATM) in the PDB file, and can
therefore be removed rather easily with a simple sed command:
sed -e ‘/^HETATM/d’ 1XYZ.pdb > 1XYZ_clean.pdb
It is also good practice to run additional quality checks on the structure before starting the simulation. The refinement process in structure determination does not always yield a proper orientation of some side-chains, such as glutamine and asparagine, given the difficulty in distinguishing nitrogen and oxygen atoms in the density mesh. Also, the protonation state of several residues depends on the pH and can influence the protein’s hydrogen bonding network. For crystal structures, the PDB_REDO database contains refined versions of structures deposited in the RCSB PDB, which address some of these problems. Alternatively, there are web servers that allow these and other problems to be detected and corrected, such as WHATIF.
Since the initial structure of the p53 peptide was generated using PyMOL and ideal geometries, there is (should be) no need to proceed with such checks.
Structure Conversion and Topology Generation
A molecule is defined not only by the three-dimensional coordinates of its atoms, but also by the description of how these atoms are connected and how they interact with each other. The PDB file, which was generated or downloaded in the previous step, contains only the former. The description of the system in terms of atom types, charges, bonds, etc…, is contained in the topology, which is specific to the force field used in the simulation. The choice of the force field must then not be taken lightly. For biomolecular systems, there are few major force fields – e.g. CHARMM, AMBER, GROMOS, OPLS – that have been parameterized to reproduce the properties of biological molecules, namely proteins. This has been, and continues to be, an area of active research since the very first day of molecular dynamics simulations. There are several literature reviews available in PubMed that assess the quality and appropriateness of each force field and their several versions. Some are well-known for their artifacts, such as a biased propensity for alpha-helical conformations. Here, in this tutorial, we will use the CHARMM36m force field, which was specifically optimized to improve backbone conformational sampling and is particularly well suited for folded and intrinsically disordered proteins. CHARMM36m has been shown to reproduce fairly well experimental data (source).
Since the simulation takes place in a solvated environment, i.e. a box of water molecules, we have also to choose an appropriate solvent model. The model is simply an addition to the force field containing the properties of the water molecule, parameterized to reproduce specific properties such as density and freezing and vaporization temperatures. As such, particular water models tend to be tied to specific force fields. Due to the difficulties of reproducing the properties of water computationally - yes, even for such a simple molecule! - some models represent water with more than 3 atoms, using additional pseudo-particles to improve characteristics such as its electrostatic distribution. The water model suggested to use with the CHARMM36m force field, and which we will use in this simulation, is the TIP3P model, specifically the CHARMM-modified TIP3P water model.
This choice is usually limited by the force field, unless there is a specific need for a particular solvent model.
Generate a topology and matching structure for the p53 peptide with GROMACS. Make sure the folder charmm36-jul2022.ff/ is present in your current working directory before running pdb2gmx. When you run the command, GROMACS will prompt you to choose a force field - charmm36-jul2022 should appear as option 1. cp -r $MOLMOD_DATA/charmm36-jul2022.ff . gmx pdb2gmx -f p53_helix.pdb -o peptide.gro -p peptide.top -ignh -ter Adjust the commands to whatever name you gave to the initial structure file.
The GROMACS program pdb2gmx takes an initial structure and returns both a new structure (peptide.gro) and a topology file
(peptide.top), that adheres to the force field atom naming
conventions. To convert the structure and build the topology, pdb2gmx divides the molecule in
several blocks, such as amino acids, and uses a force field-specific library of such building
blocks to make the necessary conversions. Usually, the matching to the library is done through
residue/atom names on each ATOM/HETATM line in the PDB file. If a residue (or atom) is not
recognized, the program stops and returns an error.
Different force fields define different atom types and/or give different names to the same atom type.
While the majority of the heavy atoms, i.e. non-hydrogen, have identical naming across most
force fields, hydrogens do not. As such, the flag -ignh indicates that GROMACS should ignore
these atoms when reading the structure and (re)generate their coordinates using ideal geometric
parameters defined in the force field. Also, the program allows the user to define the status of
the termini of the molecule through the -ter flag. Termini can be either charged (e.g.
NH3+ and COO-), uncharged (e.g. NH2 and COOH), or
capped by an additional chemical group (e.g. N-terminal acetyl and C-terminal amide).
If a peptide is part of a larger structure, then it makes sense to cap the termini in order to neutralize their charge,
as it would happen in reality.
Terminal capping should be performed prior to topology generation using the pdb_cap.py script.
This script replaces the first residue with an ACE cap and the last residue with an NME cap
by modifying atom and residue names in the PDB file, making them compatible with the CHARMM36m force field.
For capping to work correctly, the input structure must include one additional residue at both the N- and C-termini
(i.e. residues −1 and N+1 relative to the peptide of interest).
These residues act as placeholders and will be converted into caps. In practice, we add two glycine residues,
one at each end of the peptide sequence, before capping.
Capping is performed with a python script $MOLMOD_BIN/pdb_cap.py, read it’s help message to learn how to use it:
python3.10 $MOLMOD_BIN/pdb_cap.py -h
The script will produce a new file, which should then be used as input for pdb2gmx.
Once capped, pdb2gmx will recognize the ACE and NME residues automatically when using the CHARMM36m force field.
Read through the output of pdb2gmx and check the choices the program made for histidine
protonation states and the resulting charge of the peptide.
Generate a PDB file back from the converted gro file and compare it to the initial structure in PyMOL. gmx editconf -f peptide.gro -o peptide.pdb What are the differences between both files. What did GROMACS add/remove to the structure?
The newly generated topology file is also worth some attention. It contains a listing of all the residues and their corresponding atoms, detailing the atom types, masses, and charges. Further, it contains a listing of all the bonds in the molecule, the angles, and the dihedral angles. Note that the topology file does not contain any information on their chemistry. This information is stored in internal parameter libraries that are defined at the very top of the topology file.
Open the peptide.top file in a text editor and browse through it.
; Include forcefield parameters
#include "charmm36-jul2022.ff/forcefield.itp"
[ moleculetype ]
; Name nrexcl
Protein 3
[ atoms ]
; nr type resnr residue atom cgnr charge mass typeB chargeB massB
; residue 1 SER rtp NSER q +1.0
1 N3 1 SER N 1 0.1849 14.01
2 H 1 SER H1 2 0.1898 1.008
3 H 1 SER H2 3 0.1898 1.008
4 H 1 SER H3 4 0.1898 1.008
5 CT 1 SER CA 5 0.0567 12.01
6 HP 1 SER HA 6 0.0782 1.008
7 CT 1 SER CB 7 0.2596 12.01
8 H1 1 SER HB1 8 0.0273 1.008
9 H1 1 SER HB2 9 0.0273 1.008
10 OH 1 SER OG 10 -0.6714 16
11 HO 1 SER HG 11 0.4239 1.008
12 C 1 SER C 12 0.6163 12.01
13 O 1 SER O 13 -0.5722 16 ; qtot 1
Periodic Boundary Conditions
This converted structure includes several atoms, namely hydrogen, that have been added according only to ideal geometric parameters. If generated with PyMOL, it also has ideal backbone geometry. If it was otherwise downloaded from the RCSB PDB, the structure is also likely to contain certain chemical aspects (bond lengths, angles, interatomic distances) that are not considered ideal by the force field. In fact, merely changing force fields will cause the definition of ideal to change as well. The first step towards preparing the system is then to remove these “imperfections” as best as possible, which is normally achieved through an energy minimization of the system. This optimization method essentially forces a set of atoms to adhere, as best as possible, to the definitions of the force field. The larger the number of atoms in the system, the harder it is to have all of them to comply ideally with respect to all the definitions. For example, moving two atoms closer to reduce the strain from violating the definitions imposed by the van der Waals forces may cause the strain from the electrostatic term to increase.
Before minimizing the system, a general layout of the simulation setup has to be chosen. In other words, the peptide must be placed somewhere for this minimization to happen. Most modern simulations of proteins and peptides define periodic boundary conditions (PBC), which set a single unit cell that can be stacked infinitely. As a result, an infinite, periodic system is defined that avoids the problem of having hard boundaries (walls) that the molecules can literally bump into. When the protein crosses the wall on the left side, the periodic image to its right enters the current unit cell, maintaining a constant number of atoms in every unit cell. A simpler way to rationalize PBCs is to compare them to the snake game available in old Nokia cell phones. When the head of the snake crosses a boundary of the screen, it re-appears on the diametrically opposed edge.
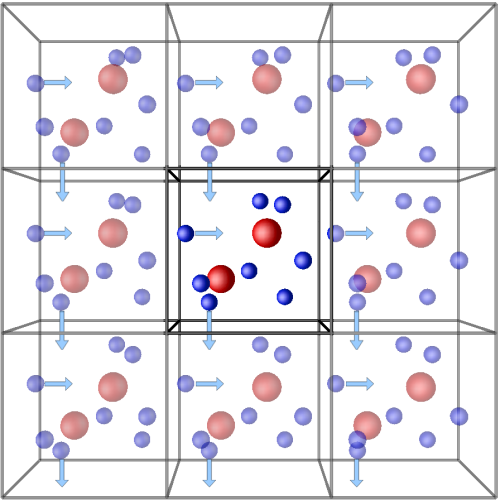
The choice of the shape of the unit cell is also important, since this will define the volume in which the molecule is simulated. Molecular dynamics simulations are computationally demanding. The more molecules in the system, the more forces need to be calculated at each step. As such, while a cube can be perfectly stacked ad eternum, it is not the most efficient shape from a volume standpoint (remember that simulations take place, usually, in a solvated environment!). Approximating the shape to a sphere is ideal, but spheres cannot be stacked. As such, only a few general shapes support the setup of periodic boundary conditions. One of those is the rhombic dodecahedron, which corresponds to the optimal packing of a sphere and is therefore the best choice for a freely rotating molecule such as a peptide or a protein.
Another thing to have in mind, when setting up the PBCs, is the size of the unit cell. Continuing with the snake analogy, it is not proper to have the snake’s head see its own tail. In other words, the cell must be sufficiently large to allow the molecule to cross the boundaries and still be at a sufficient distance from the next image that no force calculations are made between them. In GROMACS, this setting is defined as a distance from the molecule to the wall of the unit cell. This distance should not be arbitrarily large either, otherwise the box is to large and the simulation becomes computationally inefficient as your purpose is not to simulate water. Take the cutoff used to calculate non-bonded interactions (long range) in the force field as a rule of thumb. The distance to the wall must be larger than this value.
Also important is to consider possible conformational changes. The size of the box should allow for those to occur without introducing period image problems as explained above.
Setup periodic boundary conditions using a minimal distance of 1.4 nm between the peptide and the unit cell wall. gmx editconf -f peptide.gro -o peptide-PBC.gro -bt dodecahedron -c -d 1.4
As with pdb2gmx, the GROMACS program editconf generates a sizable output that contains, for
example, the volume and dimensions of the unit cell it just created. The dimensions use the
triclinic matrix representation, in which the first three numbers specify the diagonal elements
(\(xx, yy, zz\)) and the last six the off-diagonal elements (\(xy, xz, yx, yz, zx, zy\)).
What is the volume of the unit cell?
Energy minimization of the structure in vacuum
Having defined the physical space where simulations can take place, the molecule can now be energy minimized. GROMACS uses a two-step process for any calculation involving the molecules and a force field. First, the user must combine the structure and the topology data, together with the simulation parameters, in a single control file. This file contains everything about the system and ensures the reproducibility of the simulation, provided the same force field is available on the machine. Another advantage of having such a self-contained file is that the preparation can take place in one machine while the calculations run on another. Again, simulations are computationally demanding. While the system can be easily prepared on a laptop, with the help of Pymol, GUI-enabled text editors, and all the other advantages of having a screen, calculations usually run on specialized clusters with hundreds of processing cores that provide only a command-line interface access. This will be relevant when running the production simulation. The intermediate calculations to prepare the system are comfortably small to run on a laptop.
The simulation parameters are contained in a separate file, usually with the .mdp extension (for molecular dynamics parameters).
For simplicity, we provide these files in our GitHub repository) and also already in our virtual image in NMRBox, if you are using it (see $MOLMOD_DATA/mdp/).
These parameters specify, for example, the cutoffs
used to calculate non-bonded interactions, the algorithm used to calculate the neighbors of each
atom, the type of periodic boundary conditions (e.g. three-dimensional, bi-dimensional), and the
algorithms to calculate non-bonded interactions. They also specify the type of simulation, for
example energy minimization or molecular dynamics, and its length and time step if appropriate.
Finally, they describe also the frequency with which GROMACS should write to disk the coordinates
and energy values. Depending on the aim of the simulation, this writing frequency can be increased
to have a higher temporal resolution at a cost of some computational efficiency (writing takes
time). MDP files support hundreds of parameter settings, all of which are detailed in the GROMACS
manual.
Browse through the 01_em_vac_PME file, which contains the parameters for an energy minimization in vacuum. What is the algorithm used to perform the minimization? Does it assure the full convergence of the minimization?
Create a .tpr file to energy minimize the peptide structure in vacuum. gmx grompp -v -f $MOLMOD_DATA/mdp/01_em_vac_PME.mdp -c peptide-PBC.gro -p peptide.top -o peptide-EM-vacuum.tpr -maxwarn 1
Minimize the structure using the .tpr file created in the previous step, this will run for 5000 steps and it will take a few minutes. gmx mdrun -v -deffnm peptide-EM-vacuum
Although GROMACS is made of several utilities, its heart is the mdrun program.
It is this code that runs all the simulations.
The -deffnm flag is a very convenient option that sets the default
file name for all file options, both input and output, avoiding multiple individual definitions.
The -v flag tells mdrun to be verbose and in this case, print the potential energy of the
system and the maximum force at each step of the minimization.
Steepest Descents: Tolerance (Fmax) = 1.00000e+01 Number of steps = 5000 Step= 0, Dmax= 1.0e-02 nm, Epot= 4.80138e+03 Fmax= 1.83867e+04, atom= 57 Step= 1, Dmax= 1.0e-02 nm, Epot= 2.69755e+03 Fmax= 6.83824e+03, atom= 56 Step= 2, Dmax= 1.2e-02 nm, Epot= 1.46780e+03 Fmax= 4.07714e+03, atom= 57 Step= 3, Dmax= 1.4e-02 nm, Epot= 1.69036e+03 Fmax= 1.47891e+04, atom= 56 Step= 4, Dmax= 7.2e-03 nm, Epot= 1.19448e+03 Fmax= 6.00160e+03, atom= 56 Step= 5, Dmax= 8.6e-03 nm, Epot= 1.03838e+03 Fmax= 4.85784e+03, atom= 56 Step= 6, Dmax= 1.0e-02 nm, Epot= 1.11613e+03 Fmax= 1.01399e+04, atom= 56 Step= 7, Dmax= 5.2e-03 nm, Epot= 8.98891e+02 Fmax= 2.73856e+03, atom= 56 Step= 8, Dmax= 6.2e-03 nm, Epot= 8.39895e+02 Fmax= 4.76931e+03, atom= 56 Step= 9, Dmax= 7.5e-03 nm, Epot= 8.05094e+02 Fmax= 5.81049e+03, atom= 56 Step= 10, Dmax= 9.0e-03 nm, Epot= 7.77891e+02 Fmax= 5.97918e+03, atom= 56 ...
The steepest descent algorithm used in this minimization calculates the gradient of the energy of the system at each step and extracts forces that push the system towards an energy minimum. As such, the potential energy must decrease. This is not the case for molecular dynamics and other minimization algorithms. The minimization ends when one of two conditions is met:
- either the maximum force is small than the provided threshold (\(10 kJ.mol^-1\)), and the minimization converged,
- or the algorithm reached the maximum number of steps defined in the parameter file (5000).
Ideally, a minimization should run until convergence, but except for very specific scenarios, such as normal mode analysis, this is not a strict requirement.
Compare the initial structure with the energy minimized structure in PyMOL. Are there major changes in the structure of the peptide? Where are most of these located?
Solvating the simulation box
The next step is to add solvent to the simulation box. The first molecular dynamics simulations of proteins were done in vacuum, but researchers quickly realized this was a major limitation. Water molecules interact with the protein, mediating interactions between residues. In addition, water as a solvent has a screening effect for long-range interactions, such as electrostatics. In vacuum, there is nothing to prevent two opposite charge atoms to feel each other even at a very long distance, as long as they are within the cutoff used for the simulation of course. With the addition of water, this interaction is dampened significantly. The effect of water-mediated interactions are also important when choosing the size of the box. The presence of a solute, the peptide, induces a particular ordering of the water molecules in its vicinity. This might have a ripple effect that propagates the effect of the solute and causes artifacts well beyond the theoretical non-bonded cutoff.
You should have already chosen the appropriate water model – TIP3P – when running pdb2gmx. The
topology file is not required for the solvation. Essentially, this operation is just a matter of
placing pre-calculated chunks of water molecules inside the box and remove those overlapping with
protein atoms. No chemistry involved. However, the topology must be updated to reflect the
addition of the solvent.
Solvate the simulation box using the TIP3P water model. gmx solvate -cp peptide-EM-vacuum.gro -cs spc216.gro -o peptide-water.gro -p peptide.top Why can you use the coordinates of the pre-equilibrated SPC water box instead of a specific TIP3P box?
GROMACS backs up the previous topology file before updating it. Generally, GROMACS never
overwrites files, instead copying the previous one and renaming it with # symbols. At the end
of the new topology file, there is an additional entry listing the number of water molecules that
are now in the structure. It also added a definition that loads the water model parameters.
Open the solvated structure in Pymol.
Why is it not a problem to have water and/or protein atoms sticking out of the box?
Addition of ions: counter charge and physiological concentration
Besides water, the cellular environment contains a number of ions that maintain a certain chemical
neutrality of the system. Adding some of these to the simulation box also increases the realism of
the simulation. The GROMACS program genion performs this task, but requires as input a .tpr
file. The addition of ions is done by replacing certain atoms that are already in the simulation
box. Since removing atoms of the peptide is not quite desired, pay attention to the group you
select when running genion. The -neutral flag indicates that an excess of one ionic species is
allowed to neutralize the charge of the system, if there is any.
Add counter ions to the simulation box at a concentration of 0.15M. gmx grompp -v -f $MOLMOD_DATA/mdp/02_em_sol_PME.mdp -c peptide-water.gro -p peptide.top -o peptide-water.tpr -maxwarn 1 While running next command line, when asked, select the group that contains SOL. gmx genion -s peptide-water.tpr -o peptide-solvated.gro -conc 0.15 -neutral -pname NA -nname CL -p peptide.top How many ions of each species were added to the box?
cp peptide.top peptide.top.backup Inspect how the current [molecules] section is defined cat peptide.top
Energy minimization of the solvated system
The addition of ions was the final step in setting up the system (chemically) for the simulation. From here on, all that is necessary is to relax the system in a controlled manner. Adding the solvent and the ions might have caused some unfavorable interactions, such as overlapping atoms and equal charges placed too close together.
Relax the structure of the solvated peptide with another energy minimization step. gmx grompp -v -f $MOLMOD_DATA/mdp/02_em_sol_PME.mdp -c peptide-solvated.gro -p peptide.top -o peptide-EM-solvated.tpr gmx mdrun -v -deffnm peptide-EM-solvated How long did the minimization take? Why was it so much longer than the previous one?
Restrained MD – relaxation of solvent and hydrogen atoms
Despite dissipating most of the strain in the system, energy minimization does not consider temperature, and therefore velocities and kinetic energy. When first running molecular dynamics, the algorithm assigns velocities to the atoms, which again stresses the system and might cause the simulation to become unstable. To avoid possible instabilities, the preparation setup described here includes several stages of molecular dynamics that progressively remove constraints on the system and as such, let it slowly adapt to the conditions in which the production simulation will run.
The .mdp file for this simulation is substantially different from those used for the minimization
runs. First, the integrator is now md, which instructs mdrun to actually run molecular
dynamics. Then, there are several new options that relate specifically to this algorithm: dt,
t_coupl, ref_t, and gen_vel. At the top of the file, there is a preprocessing option that
defines a particular flag -DPOSRES. In the topology file, there is a specific statement that is
activated only when this flag is set, which relates to a file created by pdb2gmx – posre.itp.
This file contains position restraints for certain atoms of the system, which prevent them from
moving freely during the simulations.
Relax the solvent and hydrogen positions through molecular dynamics under NVT conditions. Copy the the .mdp file to your home directory and change the temperature (ref_t, in kelvin) and the random seed (gen_seed) used to generate initial velocities. Pick an unlikely number for the random seed (e.g. your birth date without symbols). cp $MOLMOD_DATA/mdp/03_nvt_pr1000_PME.mdp ~/ nano ~/03_nvt_pr1000_PME.mdp gmx grompp -v -f ~/03_nvt_pr1000_PME.mdp -c peptide-EM-solvated.gro -r peptide-EM-solvated.gro -p peptide.top -o peptide-NVT-PR1000.tpr gmx mdrun -v -deffnm peptide-NVT-PR1000
What is the length of the simulation in picoseconds?
The inclusion of velocity in this system caused the particles and the system to gain kinetic energy.
This information is stored in a binary file format with extension .edr, which can be read using the GROMACS utility energy.
This utility extracts the information from the energy file into tabular files that can then be turned into plots.
Select the terms of interest by typing their numbers sequentially followed by Enter.
To quit, type 0 and Enter. Use the xvg_plot.py utility to plot the resulting .xvg file, passing the -i flag to have an interactive session open.
If you want to change the colors of the plot, run the script with the -h flag and refer to this page for the available color maps.
Extract and plot the temperature, potential, kinetic, and total energy of the system.
gmx energy -f peptide-NVT-PR1000.edr -o thermodynamics-NVT-PR1000.xvg $MOLMOD_BIN/xvg_plot.py -i thermodynamics-NVT-PR1000.xvg What happens to the temperature during the simulation? What happens to the total/potential/kinetic energy and how can this be explained?
Coupling the barostat – simulating in NPT conditions
Equilibration is often conducted in two stages:
- first, the system is simulated under a canonical ensemble (NVT) in which the number of molecules, volume, and temperature are kept constant. The goal is to let the system reach and stabilize at the desired temperature.
- The second step is to couple a barostat to the simulation and maintain a constant pressure (NPT), which resembles more closely the experimental conditions.
While the temperature is controlled by adjusting the velocity of the particles, the pressure is kept constant by varying the volume of the simulation box (\(PV = NRT\)).
gmx grompp -v -f $MOLMOD_DATA/mdp/04_npt_pr_PME.mdp -c peptide-NVT-PR1000.gro -r peptide-NVT-PR1000.gro -p peptide.top -o peptide-NPT-PR1000.tpr Were you able to successfully execute the previous command? If not, read the error message carefully.
Inside 04_npt_pr_PME.mdp we define the Berendsen barostat to be used, although this weak-coupling algorithm is not rigorously compatible with a full isothermal-isobaric (NPT) ensemble.
GROMACS correctly complains about this by means of a warning message.
In our case, we are just equilibrating the system, and using the Berendsen barostat is perfectly fine.
Therefore the warning can be safely ignored by adding --maxwarn 1 at the end of the previous command.
gmx mdrun -v -deffnm peptide-NPT-PR1000 gmx energy -f peptide-NPT-PR1000.edr -o thermodynamics-NPT-PR1000.xvg $MOLMOD_BIN/xvg_plot.py -i thermodynamics-NPT-PR1000.xvg
What is better controlled: temperature or pressure? Why?
Releasing the position restraints
By now, the system had time to adjust to the injection of velocities and the introduction of both temperature and pressure. The heavy atoms of the peptide are, however, still restrained to their initial positions. The next and final steps of the simulation setup release these restraints, progressively, until the system is completely unrestrained and fully equilibrated at the desired temperature and pressure, thus ready for the production simulation.
The strength of the restraints is defined in the posre.itp file, created by pdb2gmx. The value
of the force constant defines how strictly the atom is restrained. As such, releasing the
restraints is as simple as modifying the numbers on the file.
[ position_restraints ]
; atom type fx fy fz
1 1 1000 1000 1000
4 1 1000 1000 1000
6 1 1000 1000 1000
9 1 1000 1000 1000
12 1 1000 1000 1000
13 1 1000 1000 1000
14 1 1000 1000 1000
17 1 1000 1000 1000
cp posre.itp posrest.itp.1000.backup # Make a backup of the original file sed -i -e 's/1000 1000 1000/ 100 100 100/g' posre.itp gmx grompp -v -f $MOLMOD_DATA/mdp/04_npt_pr_PME.mdp -c peptide-NPT-PR1000.gro -r peptide-NPT-PR1000.gro -p peptide.top -o peptide-NPT-PR100.tpr gmx mdrun -v -deffnm peptide-NPT-PR100
cp posre.itp posrest.itp.100.backup sed -i -e 's/100 100 100/ 10 10 10/g' posre.itp gmx grompp -v -f $MOLMOD_DATA/mdp/04_npt_pr_PME.mdp -c peptide-NPT-PR100.gro -r peptide-NPT-PR100.gro -p peptide.top -o peptide-NPT-PR10.tpr gmx mdrun -v -deffnm peptide-NPT-PR10
The final equilibration step is to completely remove the position restraints. This is done by
removing the -DPOSRES definition at the beginning of the .mdp file, while maintaining all other
parameters. For simplicity, we provide a further .mdp file without this definition (you don’t need to edit this file either).
gmx grompp -v -f $MOLMOD_DATA/mdp/05_npt_NOpr_PME.mdp -c peptide-NPT-PR10.gro -p peptide.top -o peptide-NPT-noPR.tpr gmx mdrun -v -deffnm peptide-NPT-noPR
Extract and plot the energies, temperature, and pressure. Zoom in the plot and analyse each property. Is the system finally ready to be simulated?
Production Simulation
Despite all these efforts, the system is unlikely to be in equilibrium already. The first few
nanoseconds of a simulation, depending on the system, are in fact an equilibration period that
should be discarded when performing any analysis on the properties of interest. To setup the
simulation for production, all it takes it to generate a new .tpr file that contains the desired
parameters, namely the number of steps that defines the simulation length. At this stage, there are
plenty of questions to address that have varying degrees of influence in the performance of the
calculations:
- At what time scale do the processes under study occur? How long should the simulation run for?
- What is the temporal resolution necessary to answer the research questions?
- Is there a need to store velocities and energies frequently?
- How often should the simulation information be written to the log file?
The simulation will run for 50 nanoseconds, which is sufficient to derive some insights on the conformational dynamics of such a small peptide. Bear in mind that a proper simulation to fully and exhaustively sample the entire landscape should last much longer, and probably make use of more advanced molecular dynamics protocols such as replica exchange. In this case, since several students are expected to work on the same peptide, using different random seeds and starting from different initial conformations, we assume that individual simulations of 50 nanoseconds are informative enough.
The production run can be done in NMRBox, and we will run on the cluster over the next couple of days.
To run it in NMRBox, the only step missing is to generate a .tpr file containing the information for this simulation. Give this
input file a clear name, combining the protein identifier (p53_helix, p53_extended, or p53_polypro)
with your name or initials.
Generate the production .tpr file. Copy the final 06_md_PME.mdp file to your home directory and edit nsteps it to set the number of steps necessary to reach 50 ns. Note that 1 step is not the same as 1 ns. cp $MOLMOD_DATA/mdp/06_md_PME.mdp ~/06_md_PME.mdp nano ~/06_md_PME.mdp gmx grompp -v -f ~/06_md_PME.mdp -c peptide-NPT-noPR.gro -p peptide.top -o p53_helix_CAH.tpr
MD simulations will run faster if a VM has all or most of its CPU available. You can check the CPU load for all NMRBox VMs at https://nmrbox.org/user-dashboard by looking at the “CPU Load” column.
gmx mdrun -v -deffnm p53_helix_CAH
If you wish to inspect the contents of the .tpr file, use the dump utility of GROMACS, which,
as the name indicates, outputs the entire contents of the file to the screen. Pipe the output of
the command to a text processor such as less or more (Unix joke) to paginate the output. Press
q to quit the program.
gmx dump -s p53_helix_CAH.tpr | more
Analysis of the Molecular Dynamics Simulation
The production run is only the beginning of the real work behind molecular dynamics simulations. The analysis of a simulation can be divided in several parts and varies substantially depending on the goal of the simulation and the research questions being asked. Generally, the first part of the analysis is to assess the quality and stability of the simulation in its entirety. If these indicate the simulation suffered from any problem, namely periodic image interactions, unstable temperature or pressure, or uncontrolled dynamics of the solute (i.e. unexpected unfolding of a protein), the simulation might have to be repeated. If otherwise the simulation is stable, then the analysis progresses to extract data that might help answer the research questions.
The production simulation produces a number of files, each containing different information.
Depending on the options provided to mdrun, the names may vary. The extensions, however, remain
the same. For most of the analysis, the only requirements are the compressed trajectory (.xtc)
and energy (.edr) files.
topol.tpr: Run input file, contains a complete description of the system at the start of the simulation.confout.gro: Structure file, contains the coordinates and velocities of the last step of the simulation.traj.trr: Full precision trajectory, contains the positions, velocities and forces over time.traj.xtc: Compressed trajectory, contains only coordinates (low precision: 0.001 nm)ener.edr: Energy file, contains energy, temperature, pressure and other related parameters over timemd.log: Log file containing information about the simulation, namely performance, warnings, and errors.
Quality Assurance
Before all else, it must be assured that the simulation finished properly. Many variables can cause a simulation to crash, especially problems related to the force field (if you use custom parameters) or insufficient or deficient equilibration of the system.
Check if the simulation finished properly. Verify that it ran for 50 nanoseconds. gmx check -f p53_helix_CAH.xtc How many frames are there in the trajectory? What is the temporal resolution?
Another important source of information about the simulation and its successful conclusion is the log file. Most of this file contains information on the energies at each step of the simulation. At the end, there are several tables with detailed information about the performance of the simulation.
Writing checkpoint, step 25000000 at Thu Jul 16 21:58:00 2015
Energies (kJ/mol)
U-B Proper Dih. Improper Dih. CMAP Dih. LJ-14
5.44222e+02 4.34283e+02 1.81035e+01 -2.63369e+01 1.25435e+02
Coulomb-14 LJ (SR) Coulomb (SR) Coul. recip. Potential
2.90324e+03 7.71580e+03 -9.23198e+04 2.82229e+02 -8.03229e+04
Kinetic En. Total Energy Temperature Pressure (bar) Constr. rmsd
1.50841e+04 -6.52387e+04 3.09273e+02 -3.82873e+02 2.53229e-05
<====== ############### ==>
<==== A V E R A G E S ====>
<== ############### ======>
Statistics over 25000001 steps using 250002 frames
Energies (kJ/mol)
U-B Proper Dih. Improper Dih. CMAP Dih. LJ-14
5.20505e+02 4.57178e+02 3.03600e+01 -1.14010e+01 1.26916e+02
Coulomb-14 LJ (SR) Coulomb (SR) Coul. recip. Potential
2.89500e+03 8.09479e+03 -9.32391e+04 2.85641e+02 -8.08401e+04
Kinetic En. Total Energy Temperature Pressure (bar) Constr. rmsd
1.51323e+04 -6.57078e+04 3.10260e+02 1.51651e+00 0.00000e+00
Box-X Box-Y Box-Z
4.35387e+00 4.35387e+00 3.07865e+00
Total Virial (kJ/mol)
5.04350e+03 -1.47436e-02 1.02119e+00
-1.12579e-02 5.04338e+03 -2.17245e+00
1.02255e+00 -2.17242e+00 5.04266e+03
Pressure (bar)
1.89170e+00 2.46813e-01 -2.53503e-01
2.44845e-01 9.49682e-01 8.72892e-01
-2.54285e-01 8.72874e-01 1.70815e+00
Epot (kJ/mol) Coul-SR LJ-SR Coul-14 LJ-14
Protein-Protein -3.84871e+03 -2.18949e+02 2.89500e+03 1.26916e+02
Protein-non-Protein -1.39745e+03 -2.24747e+02 0.00000e+00 0.00000e+00
non-Protein-non-Protein -8.79929e+04 8.53849e+03 0.00000e+00 0.00000e+00
T-Protein T-non-Protein
3.13254e+02 3.10150e+02
M E G A - F L O P S A C C O U N T I N G
NB=Group-cutoff nonbonded kernels NxN=N-by-N cluster Verlet kernels
RF=Reaction-Field VdW=Van der Waals QSTab=quadratic-spline table
W3=SPC/TIP3p W4=TIP4p (single or pairs)
V&F=Potential and force V=Potential only F=Force only
Computing: M-Number M-Flops % Flops
-----------------------------------------------------------------------------
NB VdW [V&F] 1606.118220 1606.118 0.0
Pair Search distance check 725959.726480 6533637.538 0.4
NxN Ewald Elec. + LJ [F] 18070249.146840 1409479433.454 84.7
NxN Ewald Elec. + LJ [V&F] 182525.653360 23545809.283 1.4
NxN Ewald Elec. [F] 2138562.944360 130452339.606 7.8
NxN Ewald Elec. [V&F] 21600.501696 1814442.142 0.1
1,4 nonbonded interactions 2328.446520 209560.187 0.0
Calc Weights 74722.738140 2690018.573 0.2
Spread Q Bspline 1594085.080320 3188170.161 0.2
Gather F Bspline 1594085.080320 9564510.482 0.6
3D-FFT 8683320.943800 69466567.550 4.2
Solve PME 40790.304000 2610579.456 0.2
Reset In Box 1245.381900 3736.146 0.0
CG-CoM 1245.387762 3736.163 0.0
Propers 2230.719750 510834.823 0.0
Impropers 169.959600 35351.597 0.0
Virial 2834.932800 51028.790 0.0
Stop-CM 249.082242 2490.822 0.0
Calc-Ekin 4981.521738 134501.087 0.0
Lincs 2283.236373 136994.182 0.0
Lincs-Mat 49011.663888 196046.656 0.0
Constraint-V 33260.265960 266082.128 0.0
Constraint-Vir 3097.710213 74345.045 0.0
Settle 9564.597738 3089365.069 0.2
(null) 42.489900 0.000 0.0
-----------------------------------------------------------------------------
Total 1664061187.059 100.0
-----------------------------------------------------------------------------
D O M A I N D E C O M P O S I T I O N S T A T I S T I C S
av. #atoms communicated per step for force: 2 x 32013.5
av. #atoms communicated per step for LINCS: 2 x 1537.9
Average load imbalance: 5.2 %
Part of the total run time spent waiting due to load imbalance: 1.7 %
Steps where the load balancing was limited by -rdd, -rcon and/or -dds: X 0 % Y 0 % Z 0 %
R E A L C Y C L E A N D T I M E A C C O U N T I N G
On 18 MPI ranks
Computing: Num Num Call Wall time Giga-Cycles
Ranks Threads Count (s) total sum %
-----------------------------------------------------------------------------
Domain decomp. 18 1 212450 667.934 31260.638 1.9
DD comm. load 18 1 212450 39.920 1868.341 0.1
DD comm. bounds 18 1 212450 106.924 5004.253 0.3
Neighbor search 18 1 212451 647.826 30319.561 1.9
Comm. coord. 18 1 4036539 3017.213 141211.619 8.7
Force 18 1 4248990 11911.658 557489.413 34.4
Wait + Comm. F 18 1 4248990 1200.017 56163.217 3.5
PME mesh 18 1 4248990 14556.938 681293.782 42.1
NB X/F buffer ops. 18 1 12322068 153.829 7199.495 0.4
Write traj. 18 1 888 0.358 16.767 0.0
Update 18 1 4248990 139.904 6547.776 0.4
Constraints 18 1 4248990 1876.305 87814.821 5.4
Comm. energies 18 1 424900 217.910 10198.637 0.6
Rest 57.370 2685.017 0.2
-----------------------------------------------------------------------------
Total 34594.107 1619073.337 100.0
-----------------------------------------------------------------------------
Breakdown of PME mesh computation
-----------------------------------------------------------------------------
PME redist. X/F 18 1 8497980 10470.597 490044.880 30.3
PME spread/gather 18 1 8497980 1694.125 79288.445 4.9
PME 3D-FFT 18 1 8497980 740.960 34678.396 2.1
PME 3D-FFT Comm. 18 1 16995960 1516.815 70989.972 4.4
PME solve Elec 18 1 4248990 125.464 5871.977 0.4
-----------------------------------------------------------------------------
Core t (s) Wall t (s) (%)
Time: 318506.837 34594.107 920.7
9h36:34
(ns/day) (hour/ns)
Performance: 21.224 1.131
Finished mdrun on rank 0 Thu Jul 16 21:58:00 2015
What percentage of the total time did GROMACS spend on calculating forces? How many nanoseconds did GROMACS simulate per day? How long did the simulation run for in real time? How much time would it need, assuming this speed, to simulate a full second?
Visually inspecting the simulation
Although most of the analysis comes down to extracting data and plotting them, molecular dynamics
is first and foremost about dynamical. As such, it is possible to extract the frames from the
trajectory and combine them into a movie. This alone can inform substantially about the integrity
of the peptide throughout the simulation. The following Pymol commands show the peptide in a
sausage-like representation colored sequentially from N- to C-terminal. To manipulate the
trajectory file, use trjconv, the GROMACS swiss-knife utility. When asked to select a group to
output, choose Protein only, otherwise you will end up with a box of slushy water molecules
obscuring the real action!
Extract 100 frames from the trajectory and visualize them in PyMOL gmx trjconv -f p53_helix_CAH.xtc -s p53_helix_CAH.tpr -o p53_helix_CAH-nojump.pdb -pbc nojump -dt 500 cartoon tube set cartoon_tube_radius, 1.5 as cartoon spectrum count, rainbow, byres=1 smooth # Optional, for less jerky movie unset movie_loop mplay
What does the -pbc nojump flag to trjconv do? What would happen if it was excluded? What happens when the peptide goes out of the box?
The peptide moves all around the box, wiggling as it diffuses through the water molecules and
beyond the boundaries of the box. When the movie is over, use the intra_fit command to align all
the frames, so that you can better observe peptide motions. Then replay the trajectory.
intra_fit name ca+c+n+o zoom vis mplay
Feel free to play around with Pymol. Zoom in on specific regions, such as where the peptide is most
rigid or most flexible, and check the side chain conformations (show sticks). Feel free to waste
some (CPU) time on making a nice image, using ray and png. Do mind that scenes that are too
complex may cause the built-in ray-tracer of Pymol to crash, so in that case you can only get the
image as you have it on screen using png directly. Check out the
Pymol Gallery for inspiration, or ask your instructors for tips. If you
have really a lot of time to waste, you can also make a movie of the trajectory, although this
is probably best done outside the virtual machine of the course, for performance reasons. You might
need to extract more frames from the simulation to make a sizable movie, depending on the frame
rate you choose.
viewport 640, 480 # No HD, unless you really want to waste time! set ray_trace_frames, 1 set ray_opaque_background, 0 mpng frame_.png
Then, in the command-line interface, assuming you are in the directory where Pymol stored all the
.png files:
convert -delay 1 -loop 0 -dispose Background frame_*.png dynamics.gif
Quantitative Quality Assurance
After a first visual inspection of the trajectory, assuming the simulation went smoothly, it is time to perform additional and more thorough checks regarding the quality of the simulation. This analysis involves testing for the convergence of the thermodynamic parameters, such as temperature, pressure, and the potential and kinetic energies. Sometimes, the convergence of a simulation is also checked in terms of the root mean square deviation (RMSD) of the atomic coordinates of each frame against the initial structure and/or the average structure. Since this simulation is of a very small and flexible peptide, it is expected that it does not converge, although there might be surprises! Finally, the occurrence of interactions between periodic images must be checked as well since, if these did occur, they might lead to artifacts in the simulation.
Convergence of the thermodynamical parameters
Start off by extracting the thermodynamic parameters from the energy file, as done previously. Of interest are the temperature, pressure, potential energy, kinetic energy, unit cell volume, density, and the box dimensions. The energy file of the simulation contains several dozen terms. Some of the energetic terms are split in groups. These groups were defined in the .mdp file and can be used to isolate specific parts of the system for future analysis, for example, looking at the interaction between specific residues.
Extract and plot the temperature from the full simulation energy file. gmx energy -f p53_helix_CAH.edr -o md_temperature.xvg $MOLMOD_BIN/xvg_plot.py -i md_temperature.xvg How does the temperature fluctuate? What is the average temperature of the simulation?
Have a look at the plot and see how the temperature fluctuates around the specified value (\(310 K\)).
The Heat Capacity of the system can also be calculated from these fluctuations. The system
temperature must be extracted from the .edr energy file together with the enthalpy (for NPT) or
Etot (for NVT) values. Furthermore, we have to explicitly state how many molecules we have in the
system with the -nmol option (you can refer to the end of the topology file to get the total
number of molecules in your system). This will allow gmx energy to automatically calculate the
heat capacity and show at the end of its output. Check the GROMACS manual for more details.
Calculate the heat capacity of your system. Find the number of molecules at the end of the topology file. gmx energy -f p53_helix_CAH.edr -fluct_props -nmol XXXX
Extract and plot the pressure, potential and kinetic energies, volume, density, and box dimensions. Does any of the parameters fail to converge? What would it mean if any didn’t? Estimate the plateau values for the pressure, volume, and density.
The equilibration of some terms takes longer than that of others. In particular, the temperature quickly converges to its equilibrium value, whereas for example the interaction between different parts of the system might take much longer.
Extract and plot the interaction energies (Coul & LJ) between the peptide and the solvent. Do they converge? What would you expect?
Calculation of the minimum distance between periodic images
A key point of any molecular dynamics simulation analysis where periodic boundary conditions were used is to check if there have been any direct interactions between neighboring images. Since the periodic images are just a trick to avoid having hard boundaries, such interactions are unphysical self-interactions and invalidate the results of the simulation.
Calculate and plot the minimum distance between periodic images. gmx mindist -f p53_helix_CAH.xtc -s p53_helix_CAH.tpr -od md_mindist.xvg -pi $MOLMOD_BIN/xvg_plot.py -i md_mindist.xvg What was the minimal distance between periodic images and at what time did that occur? Based on the cutoff distances used for the treatment of long-range non-bonded interactions during the simulation, what would be the minimum distance allowed between two periodic images? Which non-bonded energy term is most affected by a minimal distance shorter than its cutoff distance? Why?
The occurrence of a periodic image sighting can be overlooked if it is very transient and infrequent. If it does occur frequently or consistently over a stretch of the simulation, time to go back and re-do the whole setup. Also, not only direct interactions are of concern. As mentioned before, the water around the solute has a different structure than the bulk water. To be on the safe side, add an extra nanometer when calculating the allowed minimal distance.
Conformational dynamics and stability I – Radius of Gyration
Before analyzing any structural parameter, the trajectory has to be massaged to avoid artifacts because of the periodic boundary conditions. In addition, all the analysis tools work faster if the trajectory contains only the necessary (protein) atoms and their information.
Create a new reduced trajectory, by removing the effect of the periodic boundary conditions and filtering out the solvent molecules and ions. gmx trjconv -f p53_helix_CAH.xtc -s p53_helix_CAH.tpr -o p53_helix_CAH_reduced.xtc -pbc nojump
Perhaps not entirely relevant for this particular simulation, since the goal is to sample many conformations, but another part of the quality assurance of a simulation is checking the convergence of the structure itself. This can be done either by calculating the root mean square deviation (RMSD) of the atomic coordinates of each frame with respect to the initial structure or the average structure, but also by calculating the radius of gyration of the structure over the trajectory. The radius of gyration gives an indication of the shape of the molecule and compares to the experimentally obtainable hydrodynamic radius.
Calculate and plot the radius of gyration of the peptide across the trajectory. gmx gyrate -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -o md_radius-of-gyration.xvg $MOLMOD_BIN/xvg_plot.py -i md_radius-of-gyration.xvg How does the radius of gyration change with time? What does it mean if there is a prolonged period with a smaller value? Compare your results with those of other colleagues that simulated different conformations. Is there a relation between the radius of gyration and the minimum distance between periodic images? Why?
Conformational dynamics and stability II – Root Mean Square Fluctuation (RMSF)
The structure of the peptide changes throughout the simulation, but not equally. Some regions are more flexible than others, usually due to differences in the amino acid sequence. The root mean square fluctuations capture, for each atom, the fluctuation about its average position and often correspond to the crystallographic temperature (or b) factors. Comparing this experimental measure with the RMSF profile can serve as an additional quality check for a simulation. The higher the temperature factor, the more mobile the atom. An interesting collateral of this analysis is the calculation of an average structure, which can be used for future analyses.
Calculate and plot the per-residue RMSF of your peptide structure over the trajectory. gmx rmsf -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -o md_rmsf.xvg -ox md_average.pdb -oq md_temperature-factors-residue.pdb -res $MOLMOD_BIN/xvg_plot.py -i md_rmsf.xvg Which regions of the peptide show the most flexibility? Compare the results of different peptide conformations. Are there any differences? If so, which show the highest flexibility?
Load the two newly created PDB files in Pymol. Color the b-factor structure accordingly and inspect the flexible regions visually. Note the unphysical character of the average structure. spectrum b, blue_white_red, md_temperature-factors-residue as lines
Conformational dynamics and stability III – Root Mean Square Deviation (RMSD)
As the calculation of the RMSF also produced an average structure, it is now possible to calculate
the root mean square deviation of the entire trajectory. This metric is commonly used as an
indicator of convergence of the structure towards an equilibrium state. The RMSD is a distance
measure, and as such is mostly meaningful for low values. Two frames that differ by \(10Å\) from the
average structure may well be entirely different conformations. The GROMACS tools rms allows such
calculations, and in particular selecting only specific groups of atoms of the molecule, such as
the backbone.
Calculate and plot the RMSD profile vs. the initial and average structures for both backbone and all atoms. gmx rms -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -o md_bbrmsd_from_start.xvg gmx rms -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -o md_aarmsd_from_start.xvg gmx rms -f p53_helix_CAH_reduced.xtc -s md_average.pdb -o md_bbrmsd_from_average.xvg gmx rms -f p53_helix_CAH_reduced.xtc -s md_average.pdb -o md_aarmsd_from_average.xvg
Do the structures eventually converge? Which reports higher values: backbone or all-atom RMSD? Why?
While the RMSD with respect to the initial structure is relevant, if it plateaus at a relatively high value, it does not inform on the stability of the conformation. As mentioned above, two structures at \(10Å\) can be very different. For this reason, the RMSD with respect to the average structure is likely to offer a better perspective of the evolution of structural changes throughout the simulation.
Structural Analysis
Having assured that the simulation has converged to an equilibrium state, and that its results are likely to be valid, it is time for some real analysis that provides answers to a research question. Analysis of simulation data can be divided in several categories. One comprises the interpretation of single conformations according to some functions to obtain a value, or a number of values, for each time point. Example of these are the previously calculated RMSD and radius of gyration metrics. Next to that, the analysis can be done in the time domain, e.g. through averaging, such as (auto)correlations or fluctuations. In the next section, several different types of analyses will be performed, each providing a different but complementary view into the trajectory. Some might not be strictly necessary for this simulation, but are included as an example of what can be done elsewhere.
Hydrogen Bonds
Secondary structures (of proteins) are maintained by specific hydrogen bonding networks. Thus, the
number of hydrogen bonds, both internal and between the peptide and the solvent. The presence or
absence of a hydrogen bond is inferred from the distance between a donor/acceptor pair and the
H-donor-acceptor angle. OH and NH groups are regarded as donors, while O is always classified as an
acceptor. N is an acceptor by default as well, unless specifically disabled. GROMACS can calculate
hydrogen bonds over full trajectories with the hbond program. The program output informs on the
number of hydrogen bonds, distance and angle distributions, and an existence matrix of all internal
hydrogen bonds over all frames. The number of hydrogen bonds alone is a proxy for the existence of
secondary structures.
Calculate the number of internal and protein-solvent hydrogen bonds over the trajectory. Note that for determining hydrogen bonds to the solvent the reduced trajectory cannot be used. gmx hbond -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -num md_hbond_internal.xvg gmx hbond -f p53_helix_CAH.xtc -s p53_helix_CAH.tpr -num md_hbond_solvent.xvg How does the number of internal hydrogen bonds correlate with the radius of gyration? Comment on the relation between the internal and the solvent hydrogen bond populations.
In addition to global analyses, many GROMACS programs support index files, which are created with
the make_ndx program. These index files allow the creation of user-specified groups, such as
single residues or stretches of residues. For example, it is possible to evaluate the creation of
β-hairpins by checking the existence of hydrogen bonds between the two halves of the peptide.
Assume you are working on a 14-residue long peptide. The syntax within make_ndx to create an
index file to check for hydrogen bonds between the two halves is as follows:
r 1-7 name 17 half_1 r 8-14 name 18 half_2 q
Create an index file to assess the existence of hydrogen bonds that might justify a β-hairpin structure. gmx make_ndx -f p53_helix_CAH.tpr -o my_index.ndx When running the make_ndx command, pay attention to the index returned by the selection commands (r 1-7 and r 8-14), as different versions of GROMACS may return different numbers. gmx hbond -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -n my_index.ndx -num beta_hairpin_hbond.xvg
On the basis of this analysis, is your peptide adopting a β-hairpin structure during the simulation?
Secondary Structure
Among the most common parameters to analyse protein structure is the assignment of secondary
structure elements, such as α-helices and β-sheets. One of the most popular tools for this purpose
is the dssp software. Although not part of the GROMACS distribution, dssp can be freely
obtained online at the PDB REDO github page, and integrated in many of
its analysis tools. Specifically, the do_dssp tool produces a plot of the different secondary
structure elements of each residue in the peptide as a function of time. This matrix, in .xpm
format, can be converted into a Postscript file using the gmx xpm2ps tool, and then into a PDF
file using ps2pdf. The xpm2ps utility allows a scaling flag, -by, that is useful for very
short sequences, as well as a -rainbow flag that controls the coloring of the output.
Perform an analysis of the secondary structure of the peptide throughout the trajectory using
dssp.
gmx do_dssp -f p53_helix_CAH_reduced.xtc -s p53_helix_CAH.tpr -o md_secondary-structure.xpm
Did the previous command succeed? Read carefully the output to identify the problem.
In case the do_dssp command is not recognized, you may have to set the path to the dssp executable that
is installed on your machine.
export DSSP=${path_to_your_dssp_executable}
gmx xpm2ps -f md_secondary-structure.xpm -o md_secondary-structure.eps -by 20 -rainbow blue
ps2pdf md_secondary-structure.eps md_secondary-structure.pdf
Discuss the changes in secondary structure, if any.
Compare and discuss the stability of the different secondary structures in the different conformations.
Analysis of time-averaged properties
This simulation considers only one conformation. To obtain proper sampling of the peptide conformational landscape, 50 nanoseconds do not suffice. However, trajectories starting from different initial structures or starting from the same structure with a different initial random seed explore different regions of the conformational landscape. It is then desirable to combine different trajectories together and therefore obtain a much larger body of data.
Preparation of a concatenated trajectory
The first step is to trim the trajectories in order to remove the first 10 nanoseconds, which can
be conservatively considered as equilibration. This operation is possible through trjconv and its
-b flag, which allows the user to specify an offset previous to which the trajectory data is
ignored. To be able to extract only the peptide atoms, trjconv requires an dummy index file.
Trim the first 10 nanoseconds of each trajectory to discard the equilibration stage. gmx make_ndx -f p53_helix_CAH.tpr -o p53_helix_CAH.ndx gmx trjconv -f p53_helix_CAH.xtc -s p53_helix_CAH.tpr -n p53_helix_CAH.ndx -pbc nojump -dt 50 -b 10000 -o p53_helix_CAH_reduced_10-50ns.xtc
Why doesn’t it matter which topology file is used to process the different trajectory files?
After all three trajectories are trimmed, they can be concatenated using the GROMACS program
trjcat. Make sure to note down the order in which the trajectories are provided to trjcat. The
concatenation requires two particular flags to be provided as input to the program: -cat, which
avoids discarding double time frames, and -settime, which changes the starting time of the
different trajectories interactively. Effectively, the second trajectory will start at 40 ns and
the third at 80 ns. The program will prompt for an action during the concatenation: press c,
which tells trjcat to append the next trajectory right after the last frame of the previous one.
Concatenate all three trajectories into a single one for further processing. gmx trjcat -f p53_helix_CAH_reduced_10-50ns.xtc p53_sheet_CAH_reduced_10-50ns.xtc p53_polypro_CAH_reduced_10-50ns.xtc -o p53_concatenated.xtc -cat -settime
Root Mean Square Deviations – Part II
Although the root mean square deviation (RMSD) was already calculated to check for the convergence of the simulation, it can be used for a more advanced and in-depth analysis of conformational diversity. After all, the RMSD is a metric that compares structures. By performing an all-vs-all comparison with all frames in the concatenated trajectory, it is possible to identify groups of frames that share similar structures. This also quantifies the conformational diversity of a particular trajectory (or trajectories). The matrix allows also to detect and quantify the number of transitions between different conformations during the simulations. It is as relevant to have 10 different conformations or 2 that interconvert quickly. Since an all-vs-all RMSD matrix entails a very large number of pairwise comparisons, and the peptide conformations are different enough, use only backbone atoms to fit and calculate the RMSD.
Calculate and plot an all-vs-all RMSD matrix for the concatenated trajectory. gmx rms -f p53_concatenated.xtc -f2 p53_concatenated.xtc -s p53_helix_CAH.tpr -m p53_concatenated_RMSD-matrix.xpm gmx xpm2ps -f p53_concatenated_RMSD-matrix.xpm -o p53_concatenated_RMSD-matrix.eps -rainbow blue ps2pdf p53_concatenated_RMSD-matrix.eps p53_concatenated_RMSD-matrix.pdf How many groups of similar structures do you see in the RMSD matrix? Are there overlapping regions of the conformational landscape in the different trajectories?
Cluster Analysis
Using the all-vs-all RMSD matrix calculated in the previous step, it is possible to quantitatively
establish the number of groups of similar structures that a trajectory (or concatenated
trajectories) samples. Using an unsupervised classification algorithm, clustering, structures
that are similar to each other within a certain RMSD threshold are grouped together. The size of a
cluster, the number of structures that belong to it, is also an indication of how favourable that
particular region of the conformational landscape is in terms of free energy. GROMACS implements
several clustering algorithms in the cluster program. Here, we will use the gromos clustering
algorithm with a cutoff of \(2Å\). Briefly, the algorithm first calculates how many frames are within
\(2Å\) of each particular frame, based on the RMSD matrix, and then selects the frame with the largest
number of neighbors to form the first cluster. These structures are removed from the pool of
available frames, and the calculation proceeds iteratively, until the next largest group is smaller
than a pre-defined number. The cluster program produces a very large number of output files that
inform on several different properties of the clusters. Importantly, it also produces a PDB file
with the centroids, or representatives, of each cluster.
Open the resulting PDB file in Pymol and compare the centroids of each cluster with the others.
disable all intra_fit name ca+n+c+o split_states p53_concatenated_clusters delete p53_concatenated_clusters dssp all, [PATH TO DSSP e.g. /opt/bin/dssp] as cartoon
Are there any meaningful differences between the largest clusters?
Picking representatives of the simulation
The aim of this simulation exercise was to sample the conformational landscape of the p53 N-terminal transactivation peptide, in order to extract representatives that could be used to generate models of its interaction with the MDM2 protein. The last step of clustering provides an unbiased method to select structures that were sampled throughout most of the trajectory (large clusters) and are likely good candidates for seeding the docking calculations.
Congratulations!
By the end of this tutorial, you have (we hope!) learned how to setup a molecular dynamics simulation of a small peptide and how to critically interpret and validate your results. This is no small feat. The analyses we show here are just the tip of the iceberg of what you can extract from your trajectory. If you are serious about MD simulations, be sure to read the GROMACS documentation and get acquainted with the tools it offers.
You might want to use the representatives you just selected in the tutorial for data-driven docking calculations!