
(Adapted from a news item by Erwin Laure and Rossen Apostolov - KTH Stockholm)
##Introducing BioExcel
Ten European partners, including our group, have recently been awarded funding to establish a Centre of Excellence for Computational Biomolecular Research through the a project funded by the EC H2020 program, EINFRA-5-2015 (contract number 675728). The project, BioExcel, involves researchers from the KTH Department of Theoretical Physics (Sweden), from Utrecht University (Netherlands), the Institute for Research in Biomedicine (Spain), the Jülich Research Centre (Germany), The University of Edinburgh (UK), The University of Manchester (UK), the European Molecular Biology Laboratory (Germany), the Max Planck Institutes (Germany), Forward Technologies (Sweden), the Barcelona Supercomputing Center (Spain) and Ian Harrow Consulting/Pistoia Alliance (UK).
##The Need for BioExcel
The general area of life science research, which includes the more specific discipline of biomolecular research, is having a greater and greater impact on our daily lives – particularly in relation to health (as it helps in the creation of new medical treatments and drugs) and new developments in agriculture and the food production industry. Biomolecular modelling techniques have produced computational tools and programs that are widely used in applied research and industrial development. Meanwhile new technologies in imaging and gene sequencing have drastically increased the amount of data that is produced and that must be analysed. For example, state-of-the art techniques, such as cryo-electron-microscopy, depend just as much on refining data via computers as on collecting initial data through experiments. As a result of such developments, life science research is becoming increasingly “digital” rather than focussing solely on practical laboratory studies, and hence the number of people within the life science research community who are working with high-end computing is increasing. This, in turn, is creating greater and greater demands for better computational performance and throughput from the available life science computational tools.
At the same time that the life sciences are becoming critically important for the industrial sector in Europe, the use of e-infrastructures to help meet these demands is still relatively new compared to the situation in some other disciplines. (E-infrastructures are essentially networks of computational hardware and software, along with data management services and appropriate connections and communications between the various parts of the network, which are used to support collaborative research.) At present, many advanced life science computational techniques are not being applied commercially due to limited experience. Thus we have a situation where there are a lot of life science researchers who are not computing experts but who need to use complicated computationally intensive biomolecular modelling tools.
We need some way of providing these researchers with the necessary level of support so they can use the available e-infrastructures efficiently, for example, by providing suitable computational workflows to help the researchers handle the vast amounts of data that are needed for the types of calculations used in biomolecular modelling. In addition we need to improve the performance and applicability of various key life science programs and applications to handle the increasing quantities of data and enable them to run efficiently on the progressively more powerful systems that are becoming available.
Having said all of that, it is important to remember that the life sciences cover a vast field that ranges from nanoscale quantum mechanical descriptions of atomic systems (which can, for example, be used to investigate interactions between molecules) to working with whole complex organisms (such as human beings). The huge range of scales that are covered mean that the equations needed for modelling the relevant biological systems (for example, molecules, cells, brains or whole bodies) differ enormously, and hence a single Centre of Excellence cannot realistically provide adequate support for all aspects of the life sciences. This is why, given the key role of molecular-level investigations for many aspects of life sciences (including medicine, genetics, pharmacology, and the food industry), the BioExcel centre will focus on providing expertise and support for research on the main building blocks of living organisms. BioExcel will cover structural and functional studies of the building blocks of living organisms: proteins, DNA, saccharides, membranes, solvents and small molecules (like drug compounds), which are all areas that are being studied extensively in European academia and industry. Thus we will mainly work on biomolecular models up to the level of a single cell, although our expertise also covers techniques to model interactions between molecules and to handle coarser-level models for investigating the interactions between even higher levels of biological structures.
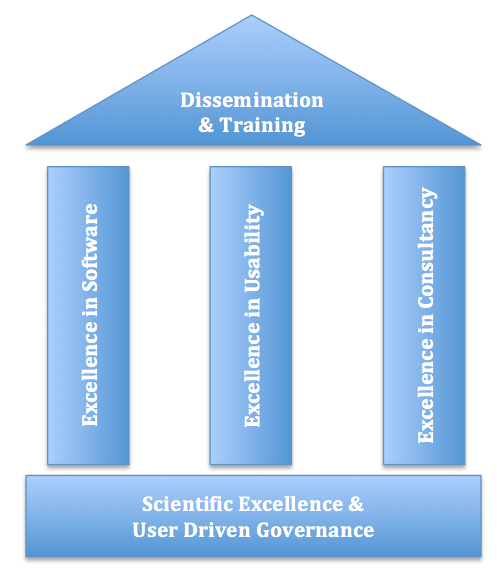
The question then is how will we help life sciences researchers make good use of the great e-infrastructures that are available to support biological research. The BioExcel project is based on three pillars: excellence in biomolecular science, excellence in application usability and excellence in consultancy and training.
##Excellence in Biomolecular Science
In terms of “Excellence in Biomolecular Science”, BioExcel personnel will improve the performance, efficiency and scalability of three of the major software codes used in biomolecular science: GROMACS, HADDOCK and CPMD, with a particular view to their use on next-generation high performance computing (HPC) systems.
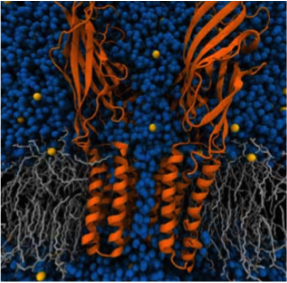
- GROMACS (http://www.gromacs.org) is an extremely widely used program for molecular dynamics simulations. It was primarily designed for running simulations of the interactions between proteins, lipids and nucleic acids – it is used both in industry, for example, for the development of novel drugs and also extensively in academic research. During simulations, scientists can observe the dynamical changes in the system, and based on the collected trajectory data understand the basis for many of the underlying phenomena.
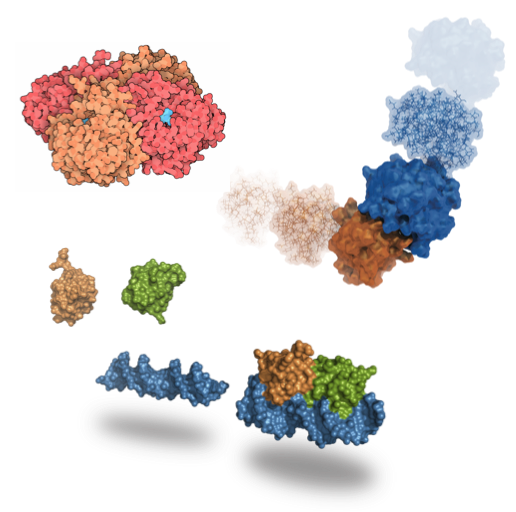
- HADDOCK (http://haddocking.org) is used for modeling the way that large molecules (macromolecules) can interact to form even larger structures or assemblies. These processes, which can change the internal structure of the initial macromolecules, are known as docking processes. The image illustrates the variety of information source that HADDOCK can use for integrative modelling of biomolecular complexes.
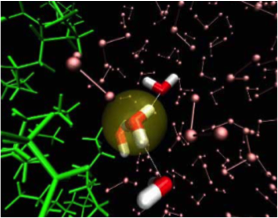
- CPMD (http://www.cpmd.org) is used to model processes using hybrid quantum mechanics/molecular mechanics methods. In the life science domain it is typically used for studying processes (for example, relating to enzymatic reactions, photochemistry and electron transfer) in which chemical bond formation and breakage are modeled and studied.
##Excellence in Usability When it comes to “Excellence in Usability”, BioExcel’s main focus will be on making it easier for academic and industrial biomolecular researchers to use the available information and communications technologies (ICT), particularly by devising efficient workflow environments with associated data integration. Workflow environments or managements systems allow people to easily set up, run and monitor a series of computational or data management tasks, without having to be programming experts. Consequently these types of easy-to-use tools are of great benefit to researchers whose expertise is in biomolecular areas, rather than in computing or data management.
##Excellence in Consultancy The purpose of BioExcel’s “Excellence in Consultancy” is to build competence amongst biomolecular researchers by training them to follow recommended “best practices” and make the best use of both the software and computational infrastructures that are available to them. BioExcel will offer help to academic/non-profit and industrial researchers who are using biomolecular software, as well as aiding academic developers of biomolecular-related software and also independent software vendors (ISVs) producing biomolecular products. The project will also be available to assist both academic HPC centres and commercial biomolecular resource providers.
##Sustainability In addition to building its three pillars of excellence, BioExcel has a fourth objective – to achieve sustainability. To this end, the project will work on developing appropriate governance structures and a sustainable business plan to enable the work of the project to continue after the initial project phase.
##BioExcel in a Nutshell In summary, BioExcel will focus on improving the usability of technologies for biomolecular researchers and also the efficiency and scalability of important software packages for biomolecular research. In addition, the project will provide training to help life science researchers make good use of the available software and e-infrastructures, and help them to be aware of the “best practices” for the relevant combinations of software and hardware. This will definitely strengthen current world leading European work in biomolecular research. It will also establish a European node in the international network of biomolecular research centres as we will be collaborating with other European projects and initiatives, such as the ELIXIR (https://www.elixir-europe.org) and INSTRUCT ESFRI (http://www.structuralbiology.eu) initiatives, e-Infrastructure projects such as PRACE, EGI and EUDAT(www.eudat.eu), and also global and national resource providers such as Amazon. In addition, BioExcel will collaborate with some of the research centres in the USA (Oak Ridge National Laboratory) and Asia (RIKEN, Japan). Important partnerships with the industrial alliances Pistoia (pharmaceuticals), CEFIC (chemicals) and FoodDrinkEurope (food industry) are also planned.
The BioExcel project officially started on the 1st of November 2015 and there was a kick-off meeting at the KTH Royal Institute of Technology in Stockholm on the 3rd of November. The project has funding for three years, however it is important to remember that one of the goals of the project is to develop sustainable resources, so the benefits of the project should continue to be available to researchers even after the initial three year period is over.
For further information about BioExcel, please see the project website www.boiexcel.eu (which was under development at the time of writing) or contact Rossen Apostolov (rossen@kth.se).